
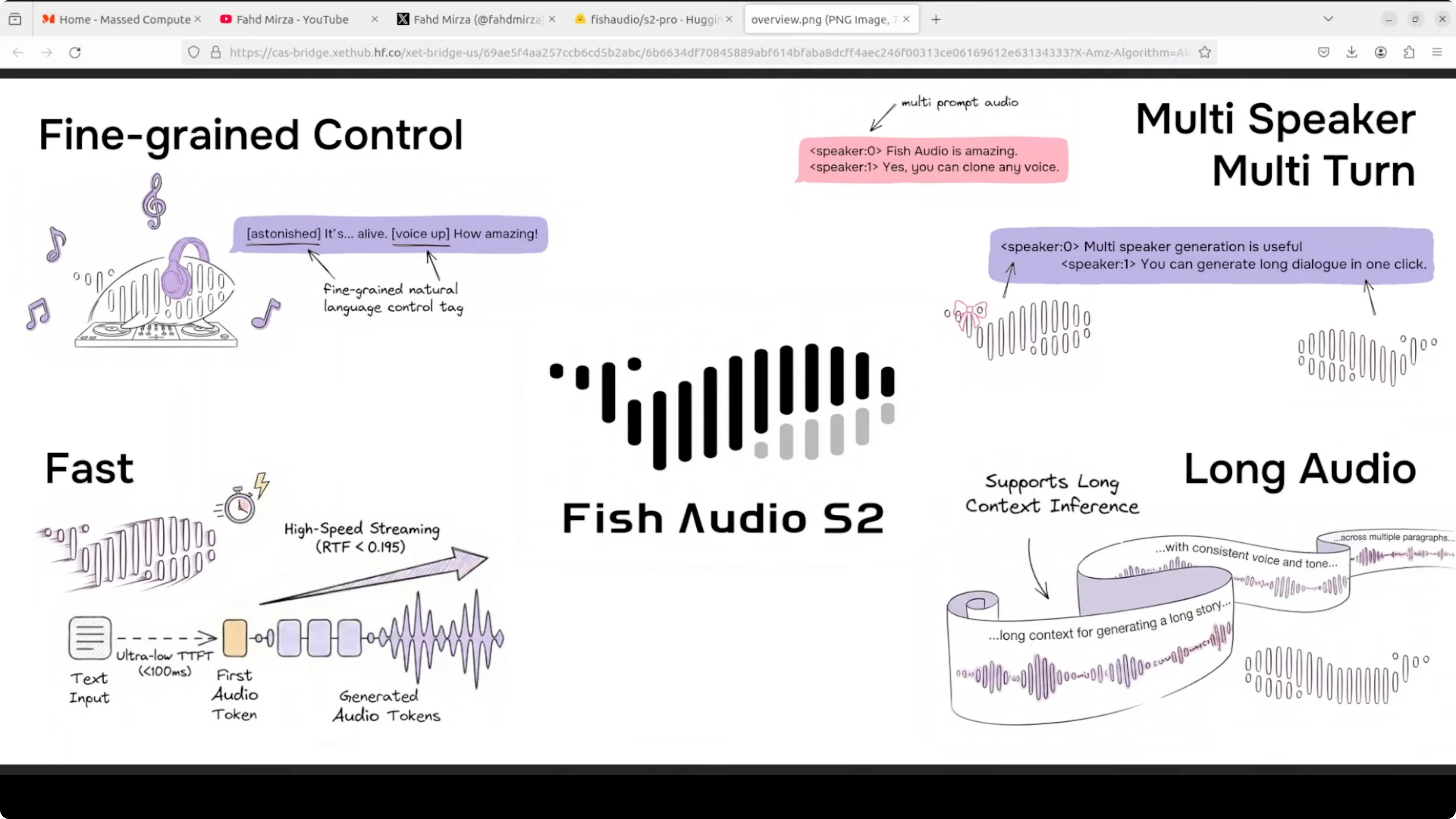
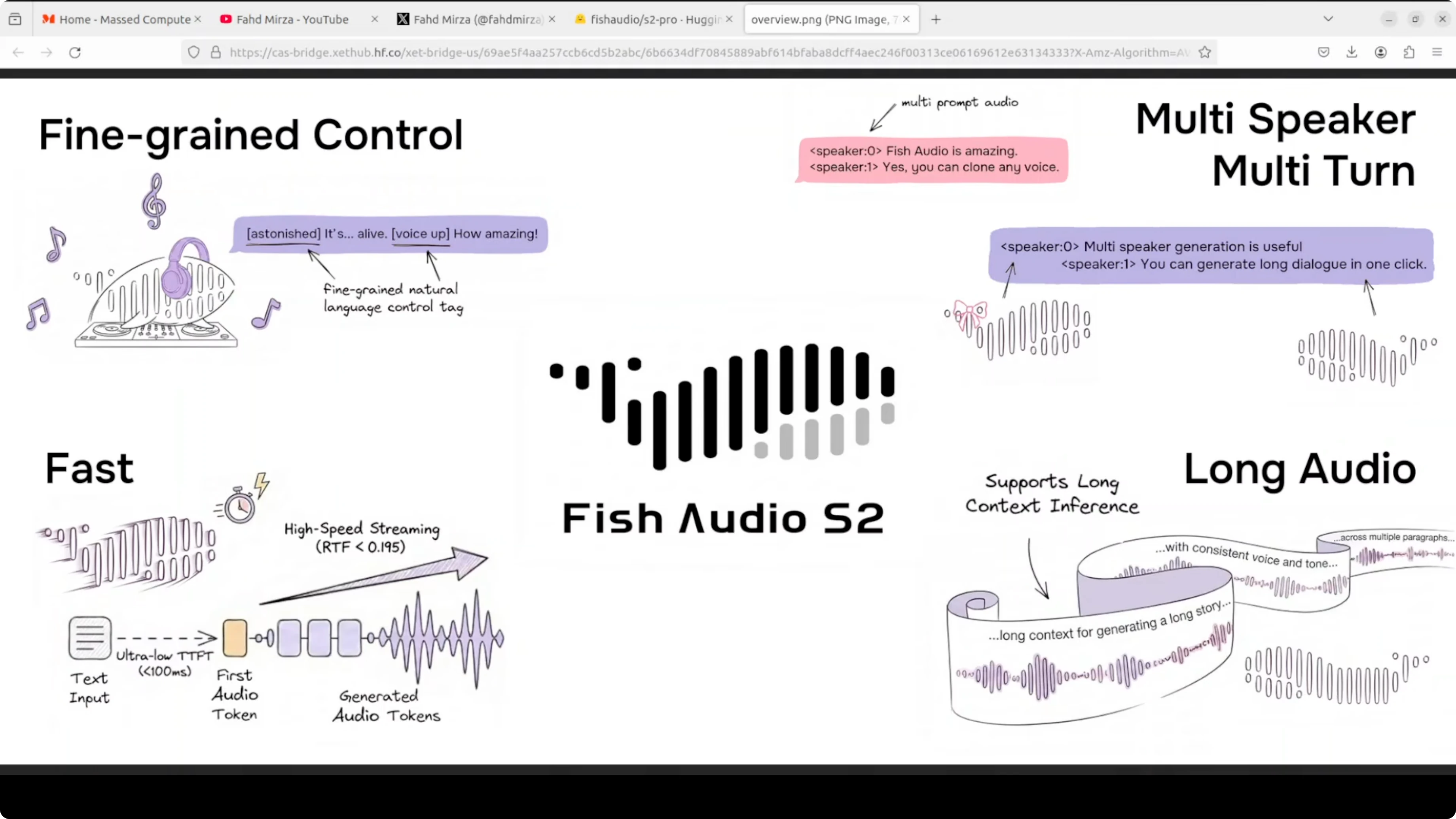
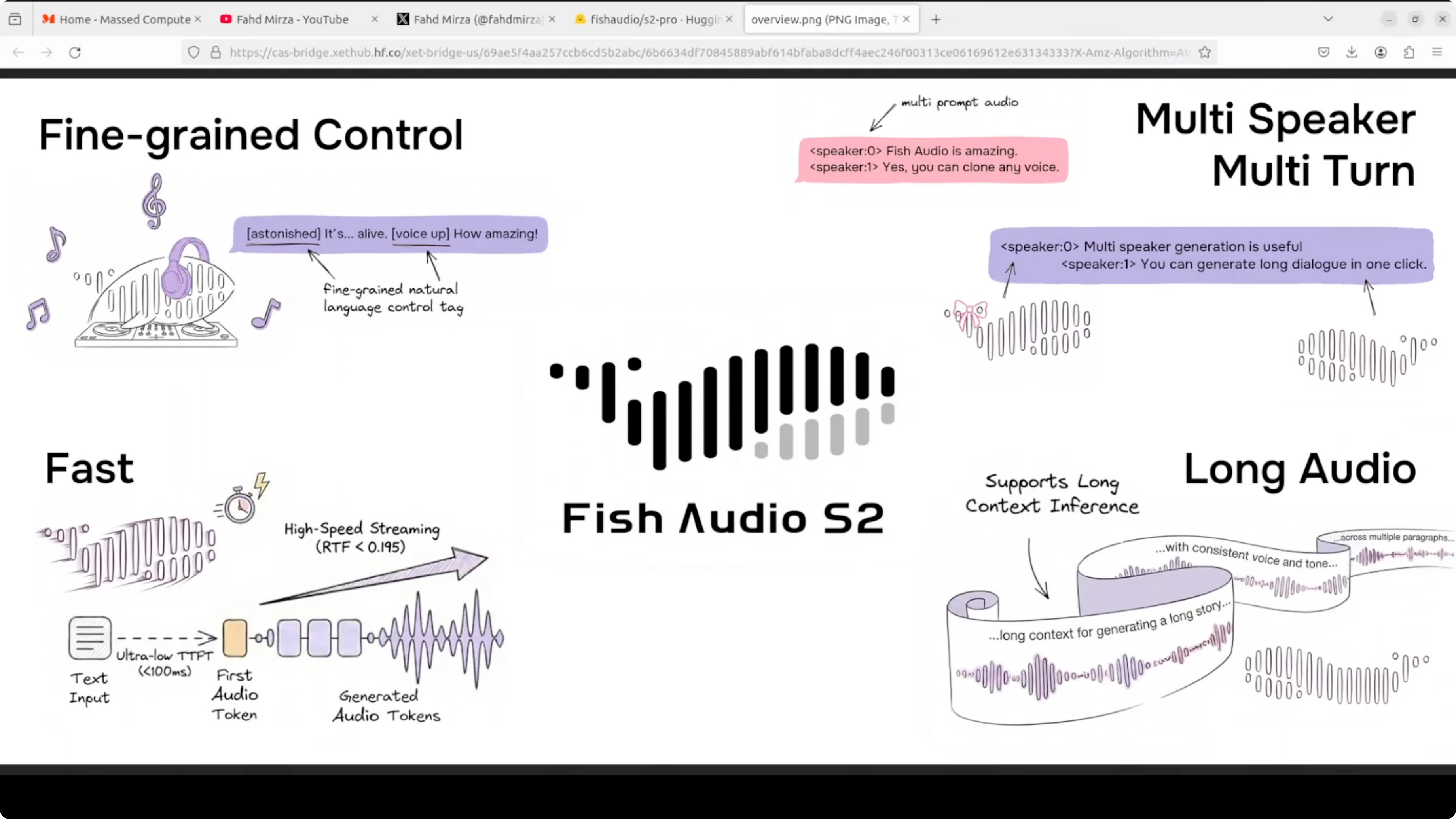
Il text-to-speech ha sempre avuto un problema: suona piatto. Nella maggior parte dei casi non riesci a distinguere se è una macchina o un umano. Fish Audio S2 Pro prova a cambiare questa situazione.
È un modello TTS open-weight che puoi eseguire in locale sulla tua macchina, addestrato su 10 milioni di ore di audio in 80 lingue. La caratteristica principale? Controlli esattamente come suona la voce inserendo tag direttamente nel testo.
Scrivi [whisper] e sussurra. Scrivi [laugh] e ride. Ci sono 15.000 tag supportati - da risate a tono da broadcaster professionista fino a descrizioni completamente personalizzate che puoi inventare tu stesso.
Fish Audio S2 Pro - Architettura Tecnica
Sotto il cofano, Fish Audio S2 Pro usa un'architettura dual model. Due reti neurali che lavorano in tandem:
Il modello grande (4 miliardi di parametri) gestisce timing e significato - la prosodia. Il modello piccolo (400 milioni di parametri) riempie i dettagli acustici.

Insieme producono audio di alta qualità velocemente - circa 100 millisecondi al primo output audio. L'inference engine è costruito su SGLang, lo stesso stack di serving usato per gli LLM. Produzione-ready fin da subito.
L'architettura usa un dual autoregressive (AR) sopra un codec audio RVQ con 10 code book a 21 kHz. Se segui gli stack LLM, riconoscerai il pattern.
Vuoi integrare AI nel tuo business?
Contattami per una consulenza su come implementare strumenti AI nella tua azienda.
Installare Fish Audio S2 Pro in Locale
Ho testato su un sistema Ubuntu con una GPU NVIDIA RTX 6000 da 48 GB di VRAM. Durante l'inferenza il consumo VRAM ha raggiunto quasi 17 GB, quindi pianifica di conseguenza.

Ti servono driver CUDA recenti e Python 3.10 o superiore.
Requisiti di Sistema
Crea un ambiente isolato e installa le dipendenze. Questo mantiene il tuo Python site pulito e riproducibile:
# Pacchetti di sistema necessari
sudo apt-get update
sudo apt-get install -y git git-lfs ffmpeg python3-venv
# Crea e attiva un virtual environment
python3 -m venv .venv
source .venv/bin/activate
python -m pip install --upgrade pip
# Installa PyTorch con CUDA (adatta la versione CUDA se necessario)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# Opzionale ma spesso richiesto
pip install sglang huggingface_hub soundfile numpy
git lfs installClona il Repository
Clona il repo che include le utility CLI e installa i requirements. Il progetto si chiama fish-speech:
# Clona repo
git clone https://github.com/fishaudio/fish-speech.git
cd fish-speech
# Installa i requirements Python
pip install -r requirements.txtScarica il Modello
Hai bisogno di un token Hugging Face per accedere ai file del modello. Il checkpoint è shardato e circa 9 GB totali:
# Login a Hugging Face
huggingface-cli login
# Scarica i pesi di S2-Pro con Git LFS
git lfs install
git clone https://huggingface.co/fishaudio/s2-pro models/s2-proNota sulla licenza: la licenza non è Apache o MIT, quindi non sembra gratuita per uso commerciale. Controlla la licenza per il tuo caso d'uso.
Scopri i miei progetti
Dai un occhio ai progetti su cui sto lavorando e alle tecnologie che utilizzo.
Voice Cloning con Controllo delle Emozioni
La web UI non funziona ancora in locale nei miei test. La CLI funziona e segue tre passaggi chiari.
Step 1 - Estrai una Voce di Riferimento
Questo passaggio prende un file audio di riferimento e lo comprime in un file NPY chiamato ref_voice. Pensalo come un'impronta digitale della voce:
# Esempio: estrai i token vocali da un WAV di riferimento
python tools/tts/encode_reference.py \
--input data/ref.wav \
--output workdir/ref_voice.npy \
--checkpoint_path models/s2-proIl modello scompone l'audio in numeri - token che rappresentano le caratteristiche uniche di quella voce. Tono, accento e texture vengono catturati.
Step 2 - Genera Token Semantici da Testo + Voce
Questo passaggio prende il testo di input più l'impronta vocale e genera token semantici. Non è ancora audio, solo un blueprint numerico di come dovrebbe suonare il parlato:
# Esempio: crea token semantici
python tools/tts/generate_semantic.py \
--text "Benvenuto nel mio canale. Oggi testiamo Fish Audio S2 Pro [whisper]." \
--ref workdir/ref_voice.npy \
--output workdir/code_0.spk \
--checkpoint_path models/s2-proÈ come se il modello scrivesse uno spartito musicale. Sa quali parole dire, con quale emozione, con quale voce, ma non l'ha ancora "cantata".
Sul mio setup, generare i token semantici ha impiegato circa 3-4 minuti. Monitora la memoria GPU con nvidia-smi se devi tenere un limite sulla VRAM:
# Guarda la memoria GPU
watch -n 1 nvidia-smiStep 3 - Sintetizza Audio dai Token
Converti i token in audio e salva un WAV. Questo è lo stage di rendering finale:
# Esempio: decodifica in audio
python tools/tts/decode_audio.py \
--codes workdir/code_0.spk \
--output outputs/output.wav \
--checkpoint_path models/s2-proIl file è salvato, puoi riprodurlo con il tuo player predefinito. Puoi scriptare tutti e tre i passaggi per eseguirli in un colpo solo.
Cerchi aiuto con l'integrazione AI?
Ti supporto nell'implementazione di soluzioni AI pratiche e scalabili.
Script Bash One-Shot
Ho messo tutti gli step in un semplice bash script così posso cambiare lingua e testo velocemente. Sostituisci i percorsi dei file secondo necessità:
#!/usr/bin/env bash
set -euo pipefail
REF_WAV="data/ref.wav"
WORKDIR="workdir"
OUTDIR="outputs"
MODEL_DIR="models/s2-pro"
mkdir -p "$WORKDIR" "$OUTDIR"
# 1) Estrai i token vocali di riferimento
python tools/tts/encode_reference.py \
--input "$REF_WAV" \
--output "$WORKDIR/ref_voice.npy" \
--checkpoint_path "$MODEL_DIR"
# 2) Genera token semantici per il testo target
TEXT="$1" # passa il testo come primo argomento
python tools/tts/generate_semantic.py \
--text "$TEXT" \
--ref "$WORKDIR/ref_voice.npy" \
--output "$WORKDIR/code_0.spk" \
--checkpoint_path "$MODEL_DIR"
# 3) Decodifica in waveform
python tools/tts/decode_audio.py \
--codes "$WORKDIR/code_0.spk" \
--output "$OUTDIR/out.wav" \
--checkpoint_path "$MODEL_DIR"
echo "Salvato: $OUTDIR/out.wav"Eseguilo per tedesco o arabo cambiando il testo di input. Puoi inserire tag come [whisper], [laugh], [excited] o [pause] direttamente nel testo per guidare l'emozione:
# Esempio tedesco
bash run_tts.sh "Willkommen. Heute testen wir Fish Audio S2 Pro [whisper]."
# Esempio arabo con hint espressivi
bash run_tts.sh "مرحبًا بكم [excited] في هذا الاختبار [pause] اليوم نجرب Fish Audio S2 Pro."Risultati e Note dall'Esperienza
Sul cloning inglese ho usato una frase tipo: "Welcome to my channel. Today we are testing Fish Audio S2 Pro and it sounds incredible."
Ha prodotto un clone molto forte della mia voce di riferimento. La qualità del voice cloning è altissima.
Ci vuole molto tempo per generare l'audio sulla mia macchina. Le espressioni come ridere o sussurrare a volte funzionano e a volte vengono perse, incluse le pause.
La multilingualità è un po' traballante, specialmente nella versione locale. Sulla versione hosted che espongono oggi ho visto solo coreano, cinese e inglese. Ho eseguito un prompt tedesco e uno arabo come sopra e ho ottenuto risultati misti sui tag espressivi.
Pro e Contro
Pro:
- Qualità del voice cloning migliorata molto in questa release. Eguaglia il livello qualitativo che mi aspetto dai migliori tool hosted in molti casi
- Controllo espressivo promettente con 15.000 tag
- Codebase basata su SGLang, quindi il design di serving si allinea con gli stack LLM moderni. Più facile pensare a scaling e monitoring
Contro:
- Velocità è il principale svantaggio nei miei test. Generare token semantici ha preso minuti e le run complete non sono istantanee su una singola GPU
- I tag espressivi mancano ancora alcuni cue come whisper e laugh nei prompt non inglesi nelle run locali
- Supporto multilingua esiste attraverso 80 lingue nel training, ma i risultati sembrano irregolari. Gli endpoint hosted che ho visto si concentrano su tre lingue per ora
Casi d'Uso Pratici
Voice cloning per narrazione long-form: puoi mantenere tono e texture consistenti mentre aggiungi sottili cue emozionali.
Workflow di localizzazione: possono beneficiare da tag strutturati, una volta migliorata la stabilità multilingua. Puoi guidare la stessa voce attraverso mercati con script specifici per lingua.
Prototipi di assistenti e sistemi IVR che necessitano controllo su prosodia e pacing possono usare i token semantici per pianificare la delivery. I team di produzione possono wrappare questi tre step CLI dietro un servizio.
Pensieri Finali
Fish Audio S2 Pro porta voice cloning locale forte con controllo fine attraverso tag testuali. La qualità è alta, le necessità VRAM sono reali, e velocità di generazione più stabilità multilingua hanno ancora bisogno di lavoro.
Mi aspetto che il team stringa i controlli espressivi e la velocità nel tempo. Per ora, la CLI a tre step è il percorso affidabile mentre la web UI matura.
Link utili: