
Abbiamo passato le ultime settimane a costruire uno stack AI locale completo. OpenClaw o le sue varianti girano come gateway di assistente personale, con agenti che schedulano lavoro mentre dormiamo. I modelli servono sulla nostra GPU o tramite API.
Ogni singolo uno di questi tool è potente. E ogni singolo uno di loro dimentica tutto nel momento in cui la sessione finisce.
memUbot è la risposta a questo. È un framework di memoria proattiva 24/7, e la parola chiave è proattiva.
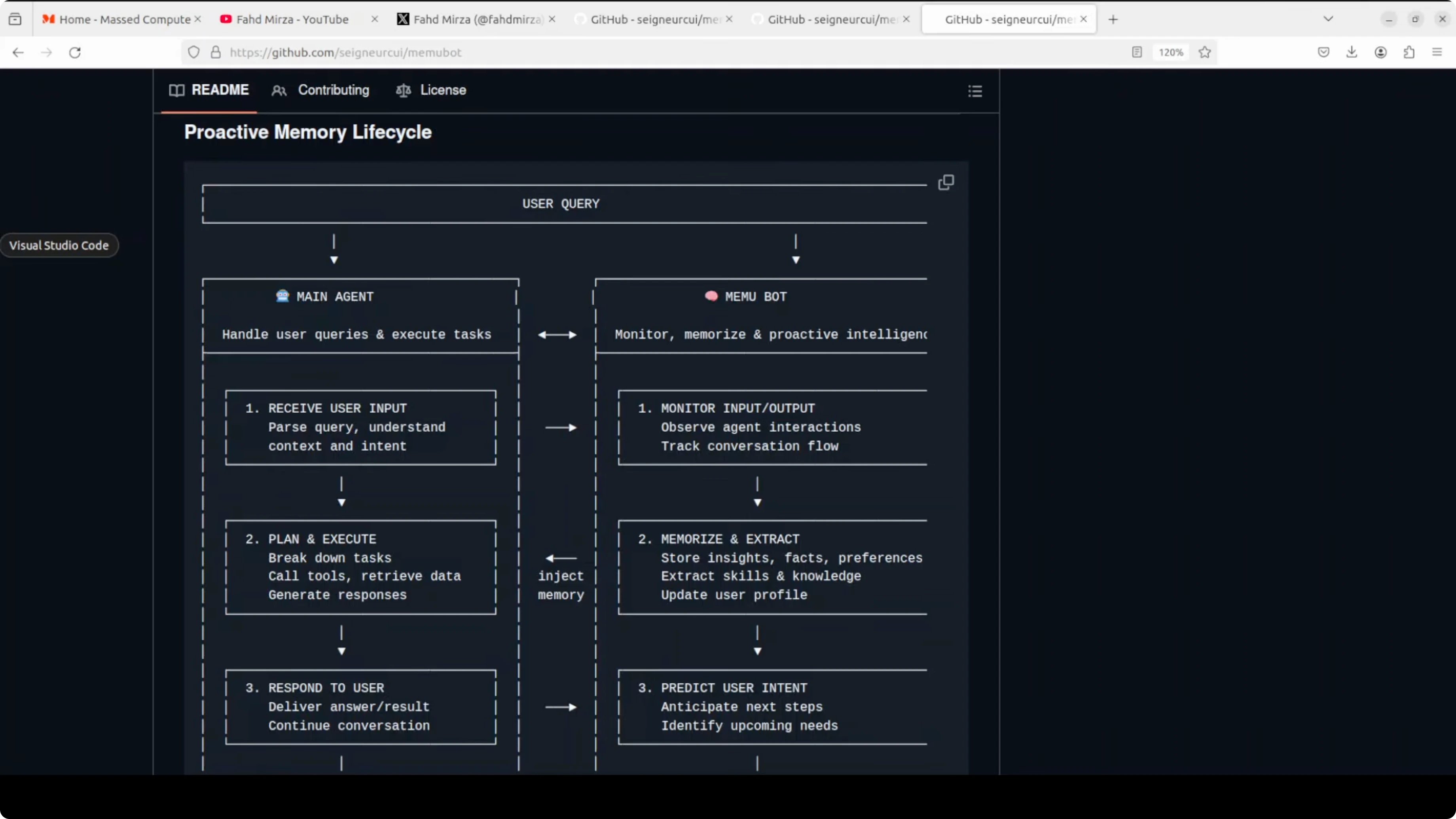
Come funziona memUbot
Fa girare due loop paralleli simultaneamente. L'agente principale gestisce le tue query, pianifica, esegue e risponde normalmente. Di lato, un memUbot dedicato osserva tutto, monitorando ogni input e output, estraendo fatti, preferenze e skill, predicendo cosa stai per fare dopo, e facendo task proattivi come pre-fetch di contesto e aggiornamento della tua to-do list in modo autonomo.
Questi due loop sono in sync continuo con un database condiviso. Il tuo agente non chiede mai a memUbot di ricordare qualcosa. memUbot semplicemente ricorda e agisce su quello che sa prima ancora che tu chieda.
Architettura: filesystem-style memory
Questa è una memoria in stile file system con documenti viventi. Non memorizza solo conversazione grezza. Capisce, estrae significato, e organizza quel significato in una struttura che un agente può navigare e su cui può agire istantaneamente.
Pensa ad attività, esperienze, obiettivi, abitudini, conoscenza, opinioni, info personali, preferenze, relazioni e persino work-life balance. Ogni categoria è un documento vivente sulla persona in quelle conversazioni. Questo corrisponde all'analogia dell'architettura dove il significato è salvato come file navigabili, non come un blob piatto.
Vuoi integrare AI nel tuo business?
Contattami per una consulenza su come implementare strumenti AI nella tua azienda.
Setup
Sto facendo girare questo su Ubuntu. Python 3.13 è un requisito hard, assicurati di averlo prima di qualsiasi altra cosa. Prendi il codice da memubot su GitHub.
Installa Python 3.13 e crea un ambiente virtuale:
python3.13 -m venv .venv
source .venv/bin/activateClona il repository ed entra nella cartella:
git clone https://github.com/seigneurcui/memubot.git
cd memubot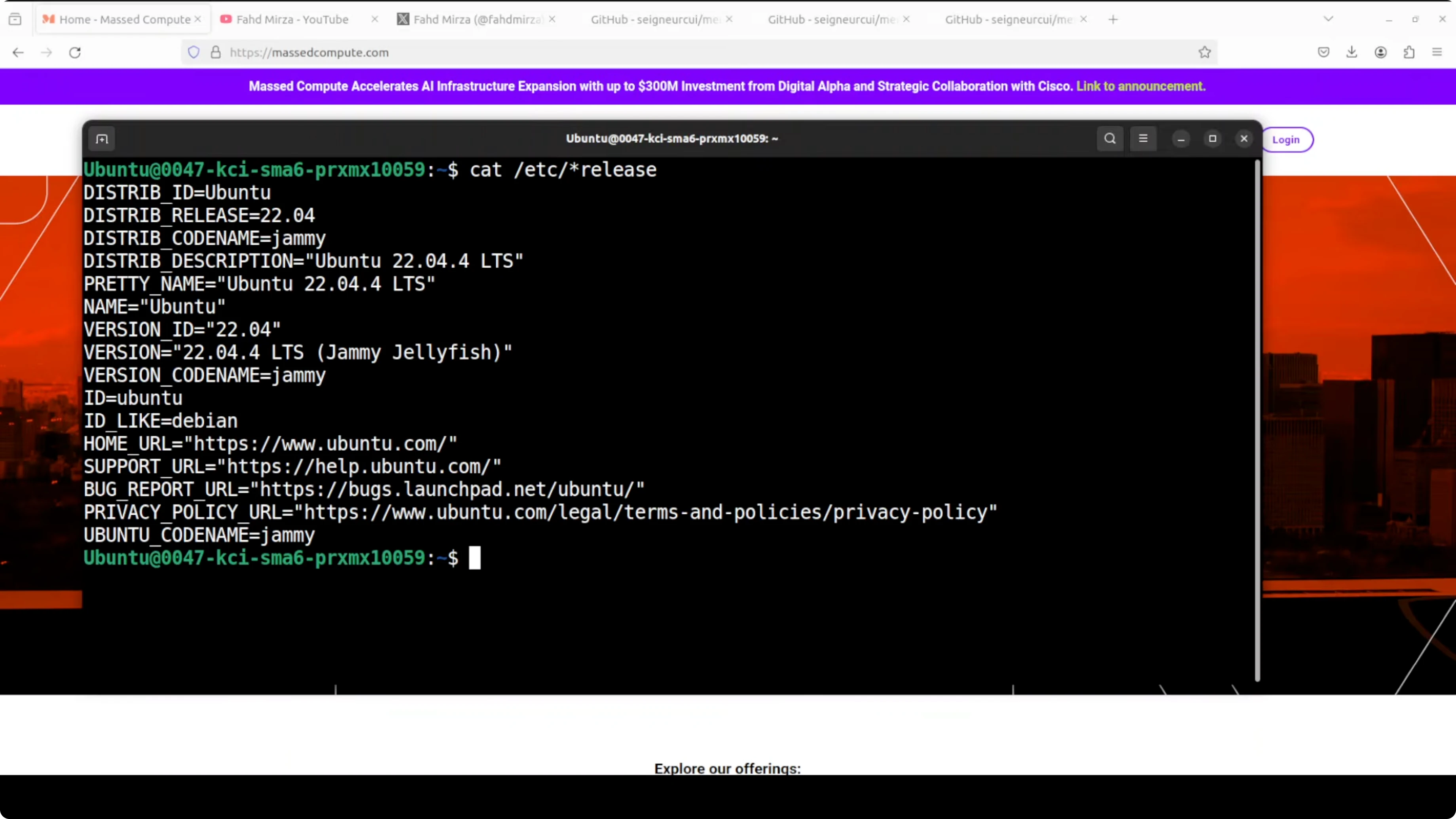
Installa i prerequisiti dalla root del repo:
pip install -r requirements.txtAssicurati che OpenClaw sia già installato e in esecuzione con il tuo modello preferito, locale o API.
Esempio con OpenRouter
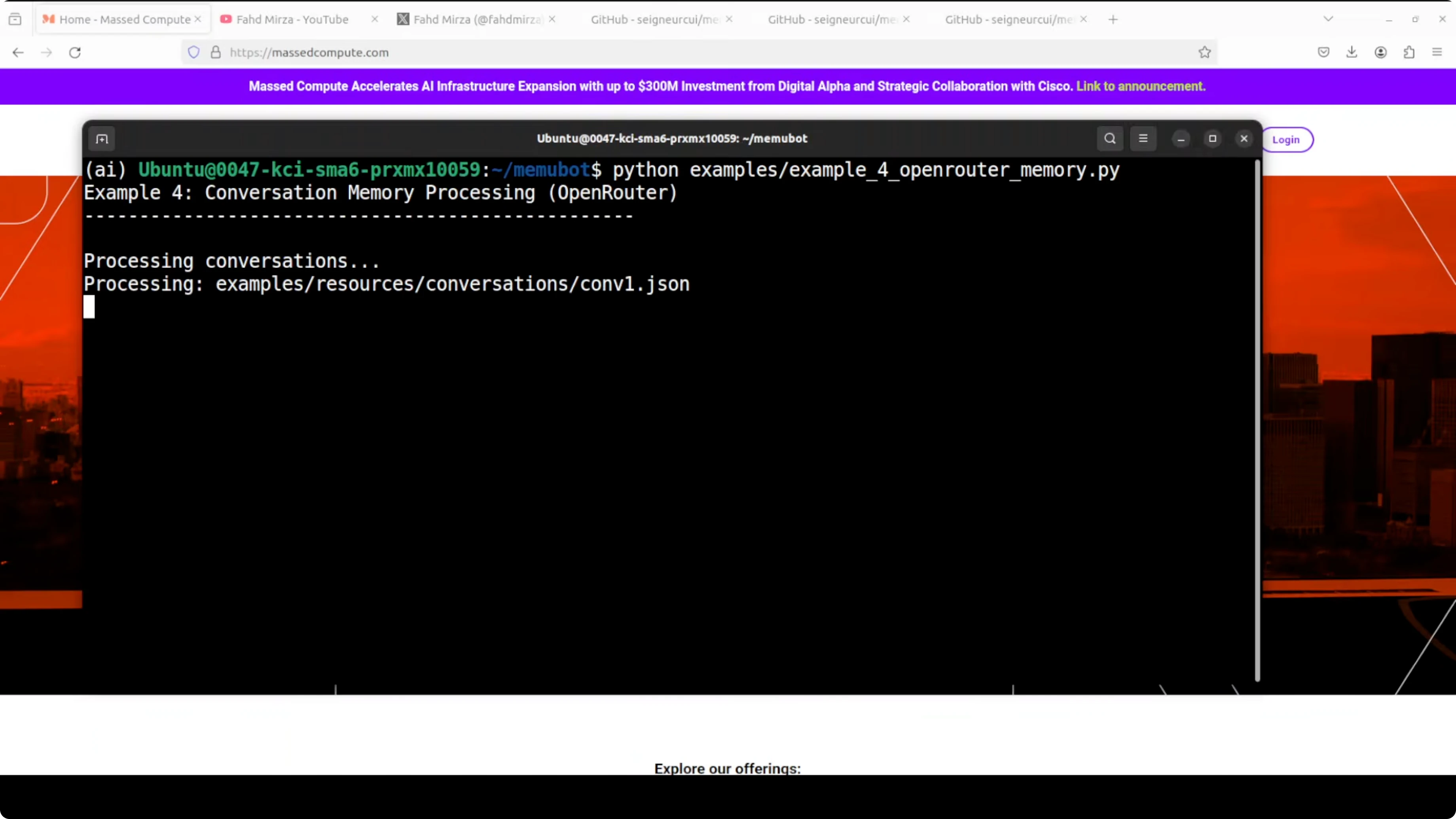
Ho fatto un esempio rapido con un modello OpenRouter che processa memoria conversazionale. Ho dato a memUbot tre file JSON di conversazioni contenenti dialoghi avanti e indietro. memUbot ha letto tutti e tre, li ha mandati a Claude via OpenRouter, e in un passaggio ha estratto 29 elementi di memoria individuali e li ha organizzati in 10 categorie automaticamente.
Non c'era istruzione su cosa ricordare e nessun tagging manuale. Ha semplicemente letto le conversazioni e capito cosa importava. L'output è un file system di memoria strutturato con cartelle come attività, esperienze, obiettivi, abitudini, conoscenza, opinioni, info personali, preferenze, relazioni e work-life balance, ognuna un documento vivente.
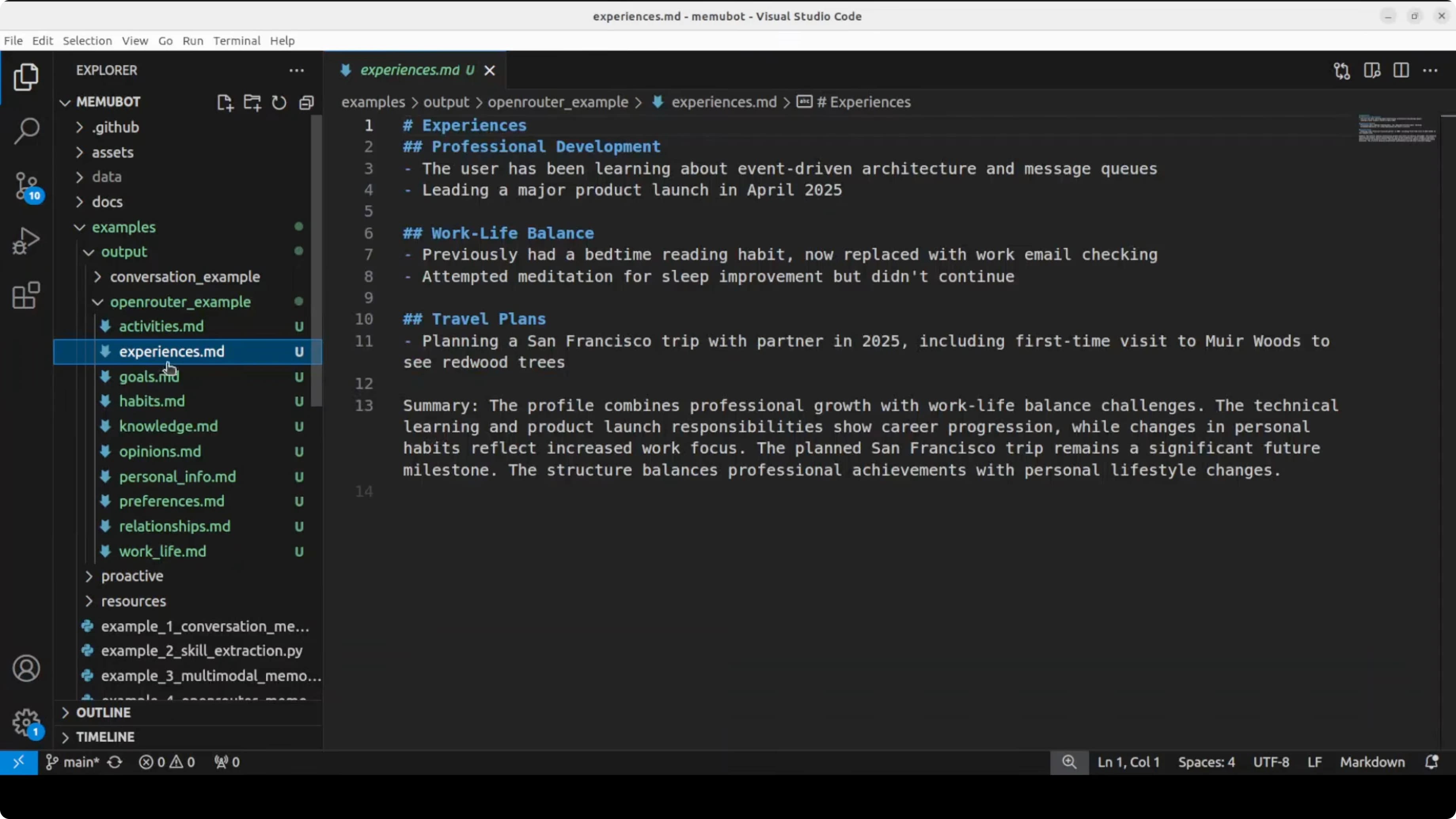
Troverai l'output nella directory outputs del repo per quell'esempio. Il punto è che memUbot non ha solo memorizzato la conversazione grezza. Ha capito e organizzato il significato in qualcosa che il tuo agente può usare istantaneamente.
Integrazione OpenClaw
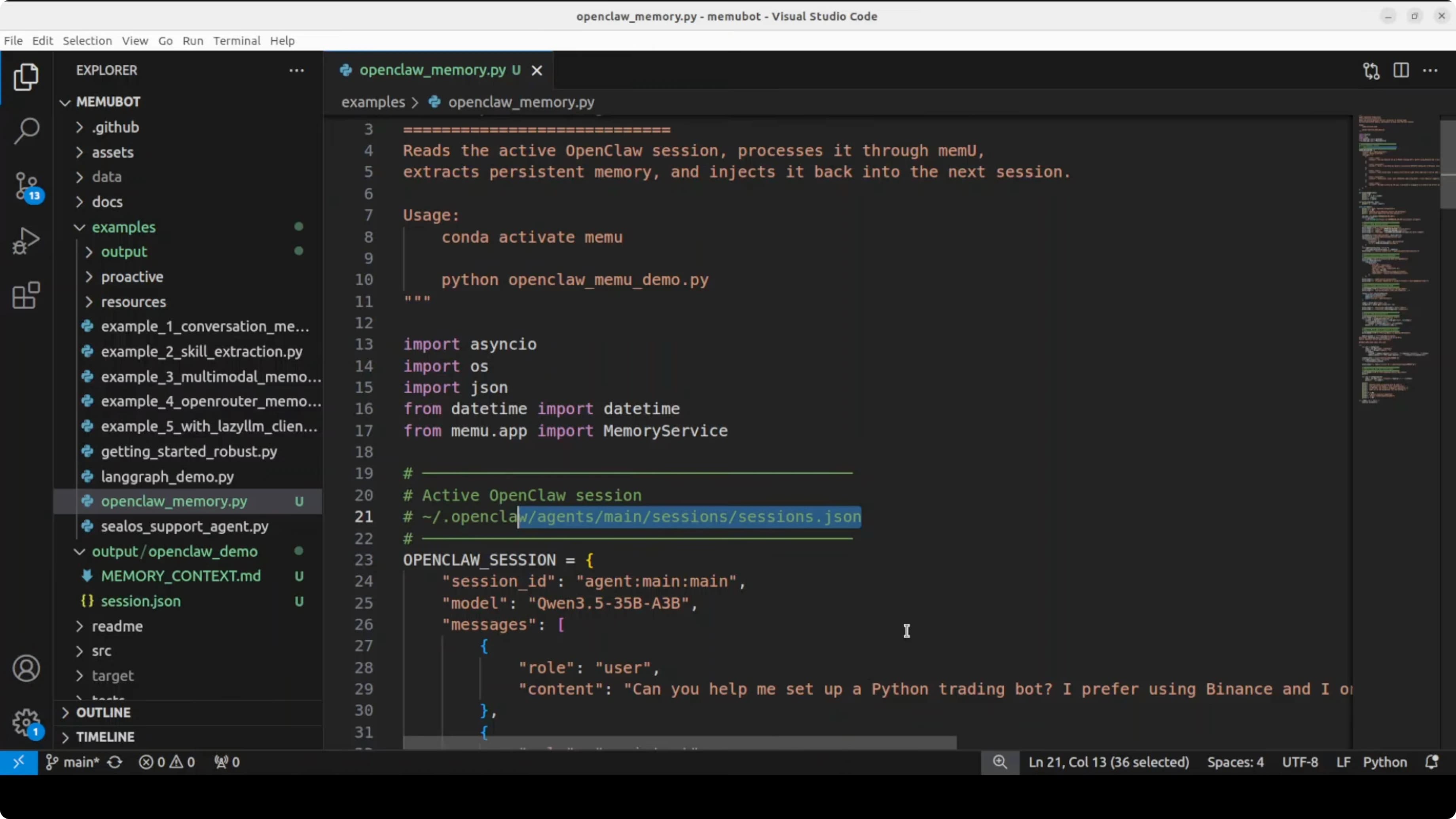
Ecco il path del codice che ho usato per integrare OpenClaw con memUbot. Prende una history di sessione OpenClaw reale dal file config.json dove abbiamo cinque messaggi tra un utente di nome Alex e l'agente su come costruire un trading bot. memUbot legge quei cinque messaggi, li manda al modello che gira con OpenClaw, scrive il file su disco, e poi crea la memoria nella directory outputs.
Prepara la tua history di sessione OpenClaw come JSON con messaggi user e assistant sul trading bot. Punta memUbot a quel session file in config.json così può ingerire la conversazione. Fai girare l'integrazione così memUbot può estrarre elementi di memoria e categorie, poi scrive memory.md nell'output.
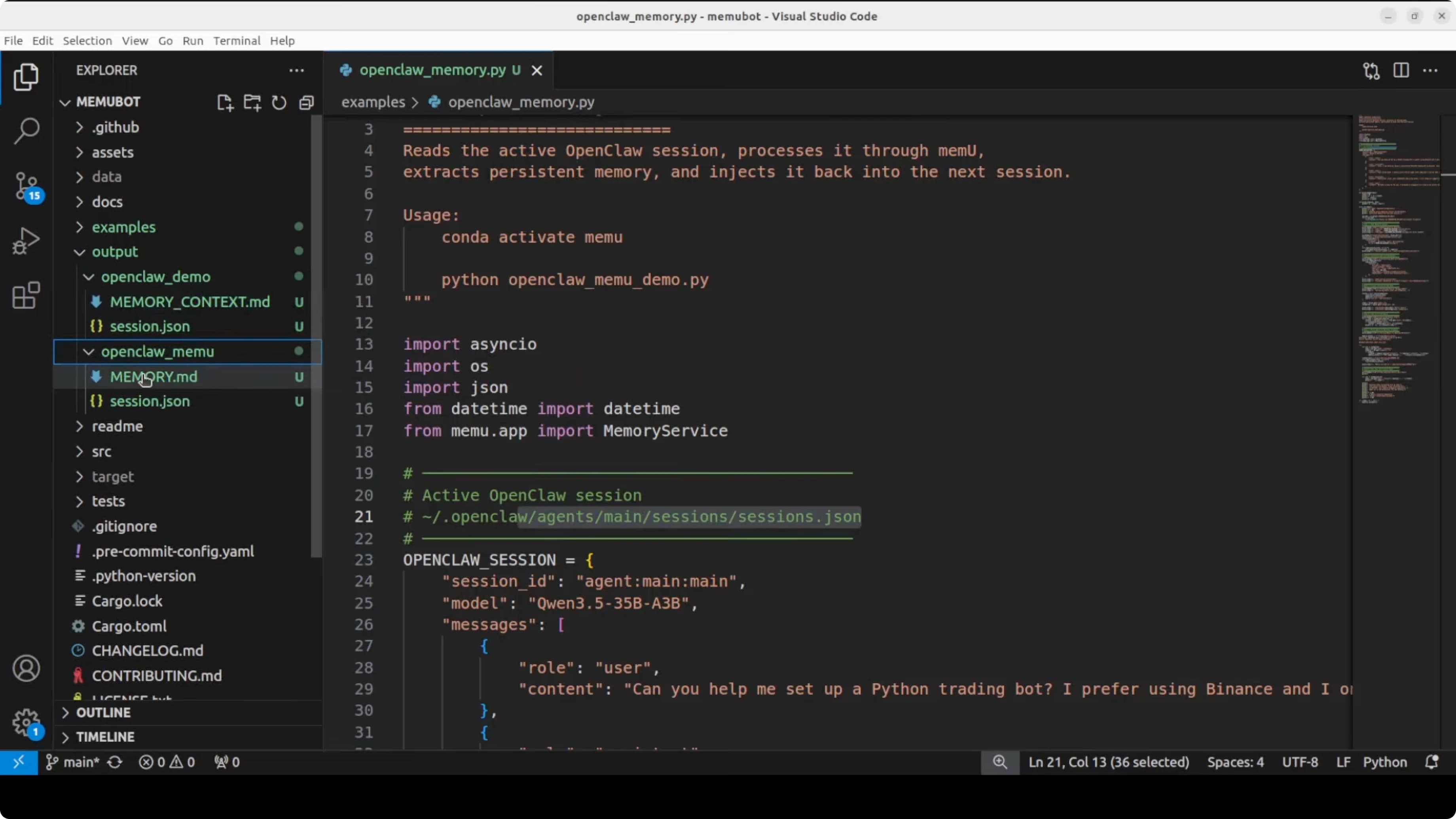
Dopo una run di successo vedrai elementi di memoria estratti e stampati durante il processing. I file sono scritti in outputs sotto una directory specifica openclaw, incluso un memory.md. La prossima volta che OpenClaw parte sa già tutto questo senza che Alex debba mai ripetersi.
Uno script, una run, e l'agente si sveglia domani sapendo tutto quello che ha imparato oggi.
Scopri i miei progetti
Dai un occhio ai progetti su cui sto lavorando e alle tecnologie che utilizzo.
Note e rough edge
Stanno facendo abbastanza bene costruendo su memu, che è già abbastanza comune e un buon tool per dare memoria agli agenti. Ci sono ancora rough edge che necessitano aggiornamenti, come l'occasionale warning JSON che hai visto. L'ho anche visto rompere un po' dato che questa è una versione molto early, e puoi costruire il tuo tool abbastanza facilmente se preferisci.
Questo spazio ha davvero bisogno di più tool, ricerca e progresso. L'idea core regge bene, e il loop proattivo più il database condiviso fanno sentire la memoria persistente. Se il tuo stack include OpenClaw e agenti correlati, questo riempie un pezzo mancante grande.
Pensieri finali
memUbot dà al tuo agente OpenClaw una memoria che non perde mai. Il loop proattivo monitora tutti gli input e output, estrae significato, e scrive memorie strutturate su cui il tuo agente può agire. Configuralo con Python 3.13, fai girare gli esempi, e lascia che il tuo agente si svegli domani sapendo già quello che ha imparato oggi.
Non è perfetto, ma è un passo solido verso agenti che davvero imparano da te invece di resettarsi ogni volta. Nel mio setup, sto considerando di usarlo per il context a lungo termine delle conversazioni con i clienti e per mantenere preferenze di progetto tra sessioni.
La cosa interessante è che puoi customizzare le categorie di memoria. Se lavori principalmente con certi tipi di info, puoi adattare lo schema. È uno strumento che cresce con te.