
Abbiamo coperto l'installazione di OpenClaw su Mac, Linux, AWS, Hostinger VPS - tutti sistemi convenzionali con sistemi operativi e gigabyte di RAM. MimiClaw butta tutto questo fuori dalla finestra.
Esegue OpenClaw su un microcontrollore ESP32 da 5 dollari senza alcun sistema operativo. Puro codice C su bare metal. L'intero loop dell'agente AI - chiamate LLM, esecuzione tool, memoria, heartbeat, cron job - gira su un chip grande quanto il tuo pollice.
Questo è il membro più radicale della famiglia OpenClaw.
Perché Eseguire Agenti AI su un Microcontrollore?
Prima di tuffarci in come funziona, la domanda ovvia: perché lo faresti?
Efficienza energetica. Un ESP32-S3 che esegue MimiClaw consuma circa 0.5 watt. È un assistente AI always-on che puoi far girare da un power bank USB per giorni.
Portabilità. L'intero setup sta in tasca. Niente laptop, nessuna dipendenza da server cloud (eccetto per l'API LLM stessa). Solo Wi-Fi e un bot Telegram.
Costo. Una dev board da 30-40 dollari. Niente bollette VPS mensili. Niente bisogno di hardware costoso.
Apprendimento. Se vuoi capire come funzionano gli agenti AI al livello più basso - gestione memoria, scheduling task, I/O di rete senza OS - questo è il rabbit hole più profondo.
È pratico per workload di produzione? Probabilmente no. Ma è affascinante, e prova che l'architettura OpenClaw è abbastanza flessibile da girare ovunque.
Come Funziona: Due Core, Zero OS
MimiClaw gira su un ESP32-S3 con due core da 240 MHz. Ecco la divisione del lavoro:
Core 0: Stack di rete - polling Wi-Fi e comunicazione Telegram Core 1: Elaborazione AI - loop dell'agente, chiamate LLM, esecuzione tool
Condividono 16 MB di storage flash SPI e 8 MB di PSRAM (RAM estesa per buffer grandi). Tutto ciò di cui il tuo assistente AI ha bisogno sta su una scheda più piccola di una carta di credito.
Tre task FreeRTOS girano concorrentemente:
- Loop dell'agente (Core 1)
- Polling Telegram (Core 0)
- Dispatcher messaggi in uscita (Core 0)
Questa divisione mantiene l'I/O reattivo mentre l'agente elabora le risposte LLM. Niente overhead di context switching da un OS completo.
No diagram code provided
Hai bisogno di integrazione AI per la tua azienda?
Contattami per una consulenza sull'implementazione di strumenti AI e automazione nel tuo stack.
Layout Memoria: 8 MB PSRAM Fa il Lavoro Pesante
La PSRAM esterna da 8 MB gestisce il working set:
- Buffer stream LLM (per risposte Claude/GPT)
- Buffer di contesto (cronologia conversazioni)
- Buffer messaggi (I/O Telegram)
Questo mantiene tutto in memoria senza paging o swapping. Niente cache filesystem, niente memoria virtuale. Solo buffer in RAM.
La flash da 16 MB contiene il codice firmware più dati persistenti:
- Cronologia conversazioni
- File di memoria
- Skill
- Cron job
È notevolmente compatto. Ogni byte ha un lavoro.
No diagram code provided
Partizioni Flash: Dove Vive Tutto
Lo storage flash è partizionato con cura:
NVS (24 KB): Storage non-volatile per credenziali Wi-Fi, API key, token Telegram. Configurato via CLI seriale.
app0 (3 MB): Partizione firmware primaria app1 (3 MB): Slot aggiornamento OTA (aggiornamenti over-the-air via Wi-Fi)
SPIFFS (9+ MB): Il filesystem on-device. Qui vivono i file dell'agente - skill.mmd, memory.mmd, log conversazioni, cron job. Tutto persiste tra i reboot.
Dopo il primo flash USB, non hai mai più bisogno di collegare un cavo. Tutti gli aggiornamenti avvengono via Wi-Fi.
No diagram code provided
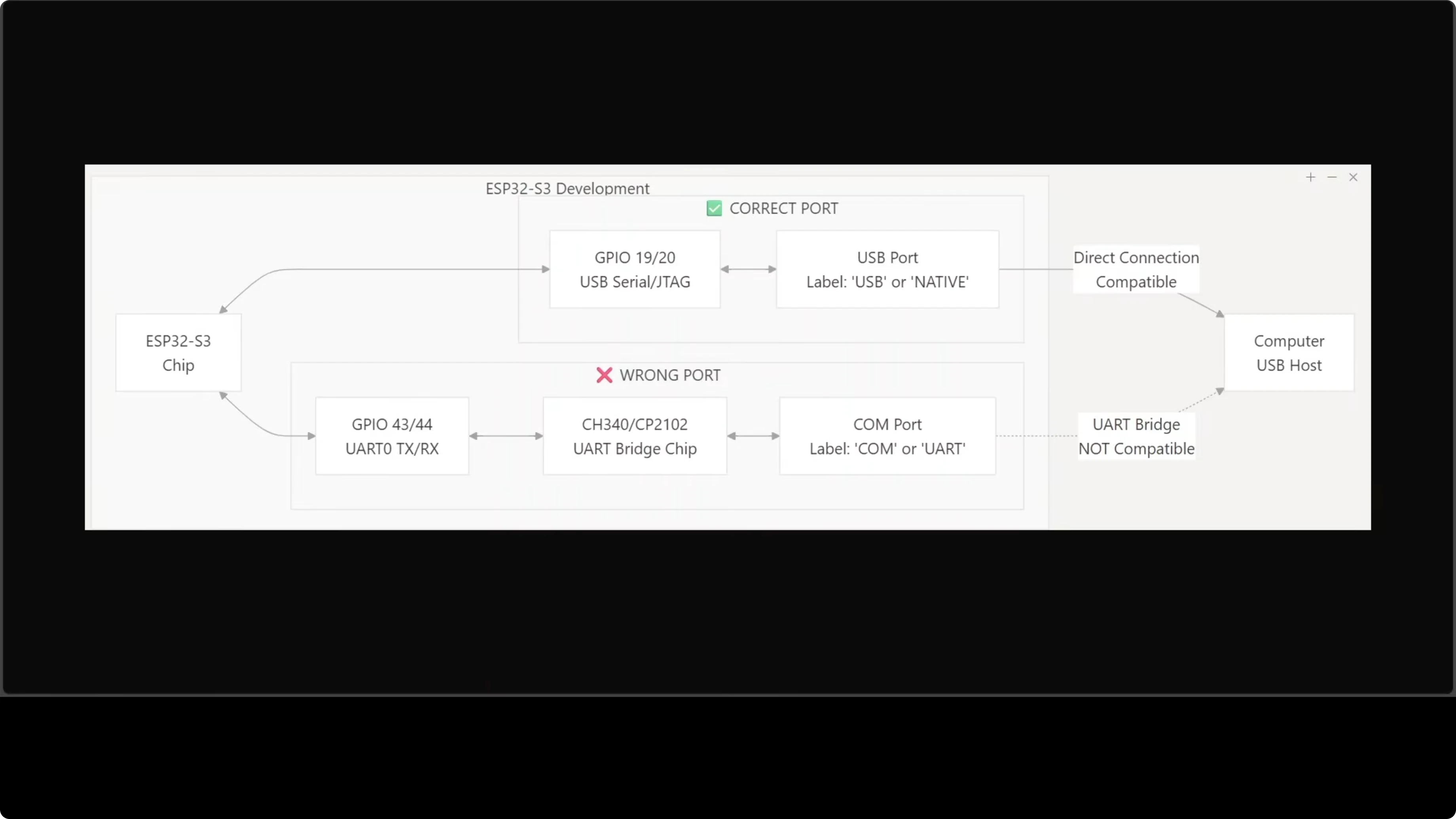
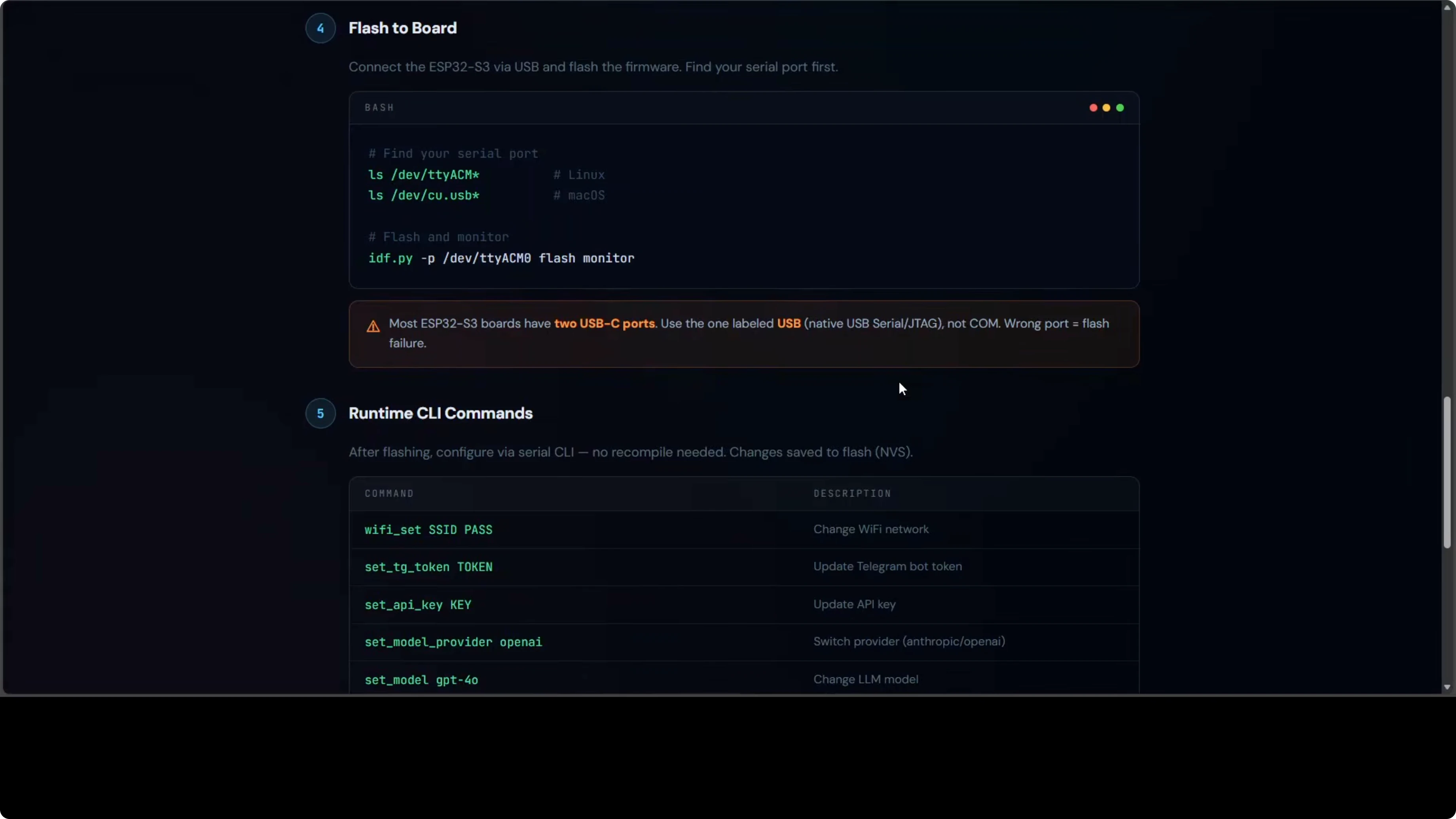
Gotcha Porta USB (Non Saltare Questo)
La maggior parte delle schede ESP32-S3 hanno due porte USB-C che NON sono intercambiabili.
Usa quella etichettata USB o Native - si connette all'interfaccia USB-Serial/JTAG integrata del chip.
La porta etichettata COM o U passa attraverso un chip bridge esterno. Il flashing attraverso di essa fallirà con errori criptici.
L'ho imparato a mie spese. Controlla attentamente la tua scheda prima di collegare. Risparmia 30 minuti di debugging.
Esplora i Miei Progetti
Dai un'occhiata a cosa sto costruendo e allo stack tech che uso per l'automazione AI.
Setup: ESP-IDF e Primo Flash
Il setup ha più passaggi delle installazioni OpenClaw solo software. Hai bisogno di ESP-IDF 5.5+ (il framework di sviluppo di Espressif per chip ESP32) su Ubuntu o macOS.
1. Installa ESP-IDF
Segui la guida ufficiale di Espressif. Questo installa la toolchain, compiler e utility di flashing.
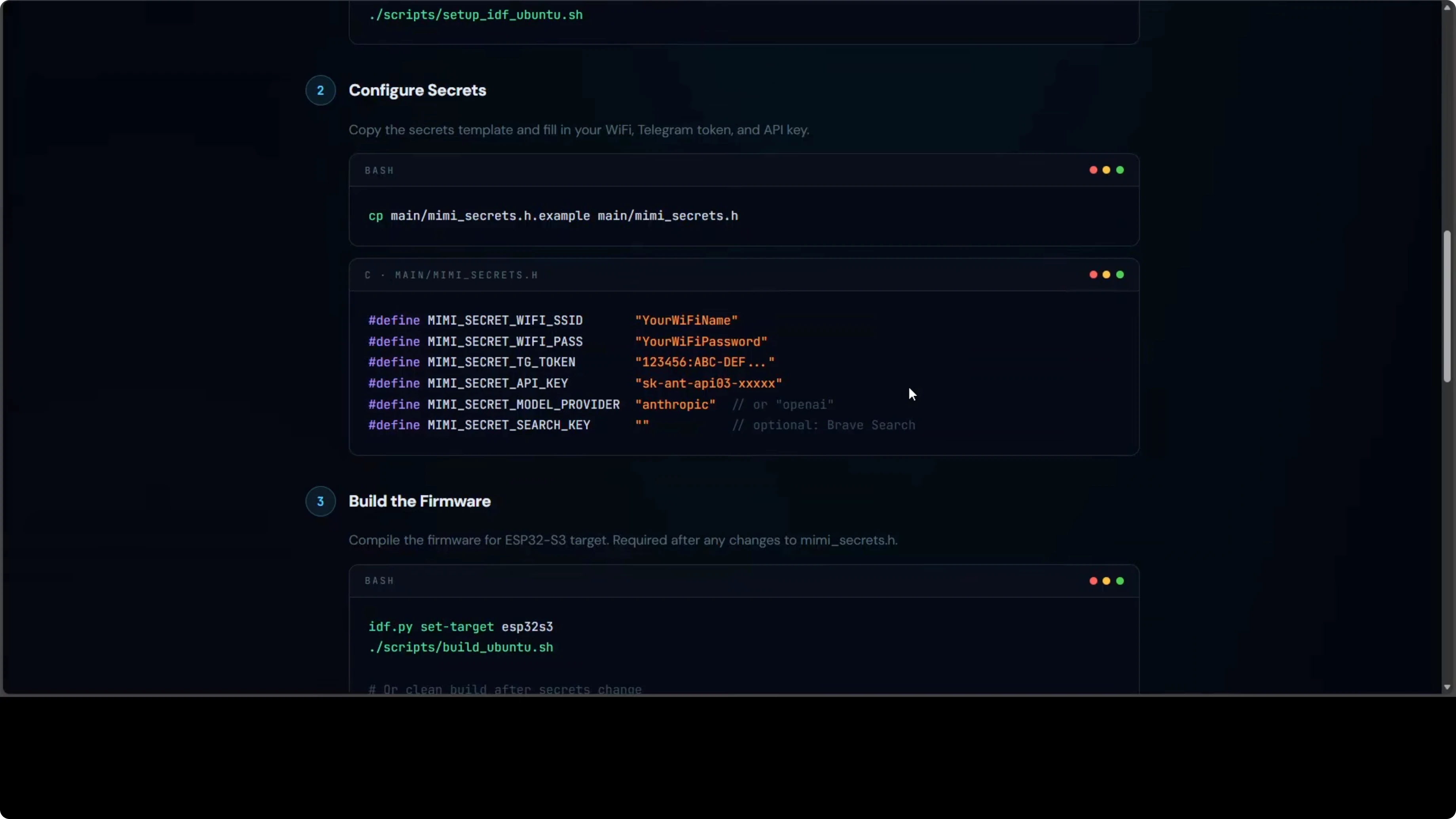
2. Clona MimiClaw e Configura i Segreti
git clone https://github.com/openclaw/mimiclaw.git
cd mimiclaw
cp secrets.example secretsModifica secrets con le tue credenziali:
WIFI_SSID="tuo-ssid"
WIFI_PASS="tua-password"
TELEGRAM_BOT_TOKEN="123456:ABC..."
ANTHROPIC_API_KEY="sk-ant-..."
OPENAI_API_KEY="sk-proj-..."
PROVIDER="openai" # o "anthropic"
MODEL="gpt-4o-mini" # o variante Claude
3. Build e Flash
idf.py set-target esp32s3
idf.py build
idf.py -p /dev/ttyACM0 flash monitorSostituisci /dev/ttyACM0 con la tua porta USB (controlla ls /dev/tty* su Linux/Mac o Device Manager su Windows).
Il comando monitor apre una console seriale che mostra log di boot e la CLI runtime.
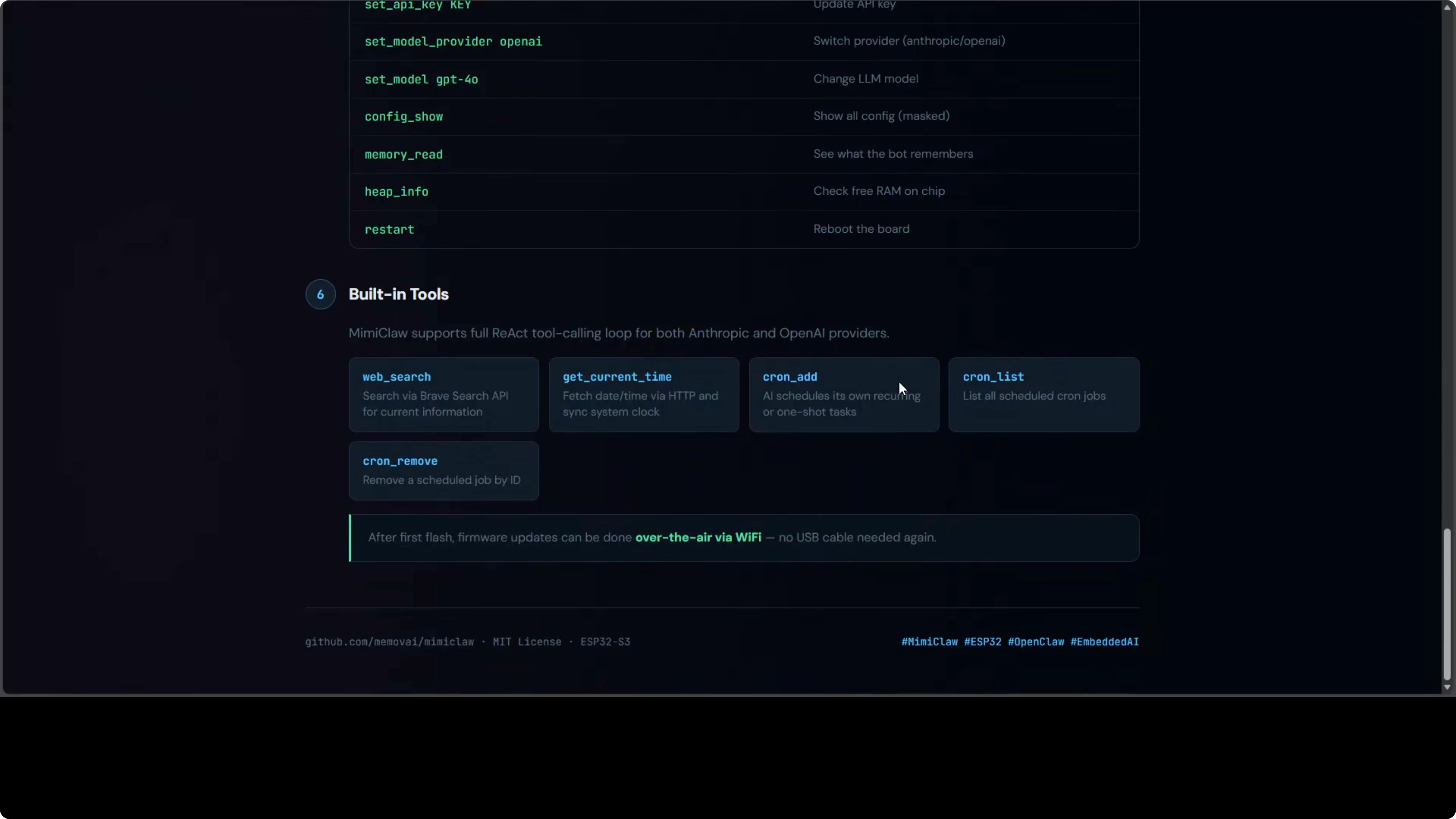
4. Configurazione Runtime (CLI Seriale)
Dopo il primo flash, puoi cambiare le impostazioni live senza ricompilare:
set wifi.ssid tuo-nuovo-ssid
set wifi.pass tua-nuova-password
set telegram.token 123456:ABC...
set provider anthropic
set api.key sk-ant-...
set model claude-sonnet-4
save
rebootTutta la config persiste in NVS tra i reboot.
Scegliere la Scheda Giusta
Cerca queste specifiche:
- ESP32-S3 (non ESP32 - sono chip diversi)
- 16 MB flash (minimo per MimiClaw)
- 8 MB PSRAM (richiesto per buffer LLM)
Alcune schede includono extra come antenne, display o camere. Non richiesti, ma non fanno male.
Il prezzo varia per regione e features. Aspettati 30-40 dollari per una scheda ben specificata.
Vuoi costruire automazione AI?
Aiuto le aziende a progettare e implementare workflow di agenti AI su misura per le loro esigenze.
Reality Check Modello Cloud
L'hardware è economico. La scheda gira con poco. Ma hai comunque bisogno di una API key LLM.
MimiClaw supporta:
- Anthropic Claude (Sonnet, Opus, Haiku)
- OpenAI GPT (4o, 4o-mini, o1)
Switchabile a runtime via CLI seriale. Il modello gira nel cloud. Il chip gestisce il loop dell'agente, memoria e comunicazione Telegram.
Paghi per le chiamate API anche se il costo hardware è basso. Non è una soluzione completamente offline - ma è il più vicino possibile a un assistente AI standalone che sta in tasca.
Cosa Non Puoi Fare (Ancora)
MimiClaw è impressionante, ma ha limiti:
Niente LLM locali. L'ESP32 non ha la potenza per eseguire nemmeno piccoli modelli quantizzati. Solo API cloud.
Niente upload di file. I vincoli di memoria significano niente analisi immagini, niente elaborazione PDF, niente gestione file grandi.
Niente automazione browser. Il chip non può eseguire Playwright o Puppeteer. L'uso di tool è limitato a chiamate API ed elaborazione testo.
Storage persistente limitato. 9 MB SPIFFS sono sufficienti per cronologia conversazioni e skill di base, ma non puoi conservare grandi dataset o costruire un sistema RAG.
Per quei workload, resta con OpenClaw basato su server. MimiClaw è per assistenti AI always-on, a basso consumo, portatili con esigenze computazionali modeste.
Quando Usare MimiClaw
Ecco dove ha senso:
Assistenti AI IoT. Sensori, automazione casa, monitoraggio remoto con interfacce linguaggio naturale.
Assistenti personali portatili. Un bot Telegram che puoi portare ovunque con accesso internet.
Imparare AI embedded. Se vuoi capire come funzionano gli agenti AI al livello più basso, questa è l'immersione più profonda.
Ambienti con vincoli di potenza. Setup alimentati a solare, dispositivi alimentati a batteria, deployment edge dove ogni watt conta.
Prototipare prodotti AI hardware. Testa workflow di agenti su hardware embedded reale prima di scalare.
Non è per tutto. Ma quando il caso d'uso si adatta, è magico.
Considerazioni Finali
MimiClaw è il membro più radicale della famiglia OpenClaw. Puro C su un ESP32-S3 senza OS. Due core divisi tra networking e AI. Un layout di memoria e flash compatto che mantiene tutto persistente.
Un assistente AI always-on che consuma 0.5 watt e risponde via Telegram è genuinamente speciale.
Non è il setup OpenClaw più potente. Ma è il più portatile, il più efficiente dal punto di vista energetico e il più affascinante dal punto di vista ingegneristico.
Se ti sei mai chiesto quanto in basso puoi andare pur eseguendo un agente AI funzionale - questa è la risposta. Un chip da 5 dollari con core da 240 MHz e 8 MB di RAM è sufficiente.
Il futuro dell'AI non è solo nei data center. È anche in tasca, sulla scrivania, embedded nei dispositivi che usi ogni giorno. MimiClaw è uno sguardo a quel futuro.