
Ogni assistente AI che ho usato ha una cosa in comune: è statico. Ci chatti oggi, ci chatti domani, ed è esattamente lo stesso. Non impara dalle tue correzioni, dalle tue preferenze, dal tuo modo di lavorare.
OpenClaw-RL cambia tutto. È un framework di reinforcement learning che trasforma le tue conversazioni quotidiane in segnali di addestramento. Gli dai un pollice su, una correzione, o un'istruzione concreta tipo "avresti dovuto controllare quel file prima", e il modello si aggiorna in background.
Non è fine-tuning su dataset di altri. È il tuo modello addestrato sulle tue conversazioni sulla tua infrastruttura, senza mai uscire dal tuo server.
Cos'è OpenClaw-RL?
OpenClaw-RL è un framework di reinforcement learning completamente asincrono che si adatta alle tue abitudini, alle tue preferenze, al tuo stile di lavoro. A differenza del fine-tuning tradizionale che richiede raccolta dati, annotazione e training job costosi, OpenClaw-RL impara continuamente dalle tue interazioni naturali.
Il concetto chiave: il tuo prossimo messaggio in una conversazione è feedback sulla risposta precedente. Se correggi l'agente, chiarisci qualcosa, o semplicemente continui la conversazione naturalmente, sono tutti segnali di training.
L'Architettura: Quattro Componenti Che Non Si Bloccano Mai
Il sistema è costruito su quattro componenti asincrone indipendenti che girano in parallelo senza bloccarsi a vicenda:
No diagram code provided
- Client OpenClaw - Il tuo assistente su qualsiasi device, manda le conversazioni al model server
- Model server - Serve l'agente live come API compatibile OpenAI sulla porta 30000
- PRM server - Un process reward model che valuta ogni turno e gli assegna un punteggio
- Training engine - Esegue aggiornamenti dei gradienti in background, manda i pesi aggiornati al model server
Il loop è continuo. Stai chattando con l'agente mentre si sta addestrando, e nessuno dei due blocca l'altro. Questa è la vera innovazione - la maggior parte dei setup RL richiede di fermare il modello per addestrarlo. OpenClaw-RL continua a servire mentre migliora.
Hai bisogno di aiuto con l'integrazione AI?
Contattami per una consulenza su come implementare strumenti AI nella tua azienda.
Due Metodi di Addestramento
OpenClaw-RL supporta due approcci per imparare dalle conversazioni:
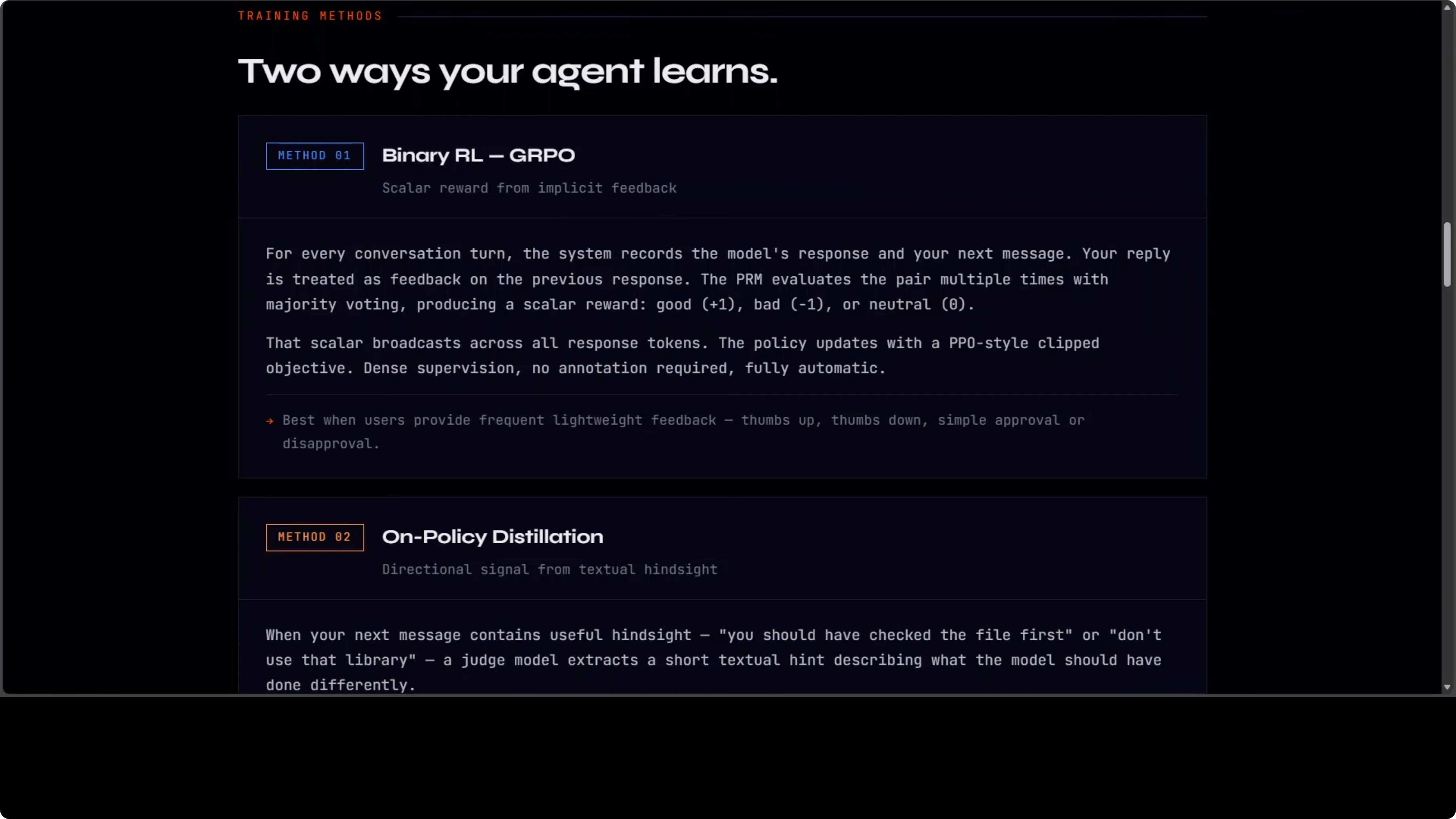
RL Binario (GRPO + PPO)
Il primo metodo tratta il flusso conversazionale come feedback implicito. Per ogni turno, il sistema registra cosa ha detto il modello e cosa hai detto tu dopo. Il tuo messaggio successivo è trattato come feedback sulla risposta precedente.
Un process reward model vota se quella risposta è stata buona, cattiva o neutra. Quel reward scalare viene distribuito su tutti i token della risposta, e la policy si aggiorna usando un obiettivo clipped stile PPO.
Semplice, denso, automatico. Nessuna annotazione richiesta. Il flusso naturale della chat diventa un flusso costante di segnali di apprendimento.
Hint Direzionali
Questo è il metodo più potente quando dai feedback esplicito. Quando dici al modello cosa avrebbe dovuto fare diversamente, un judge model estrae un breve hint testuale da quel feedback.
Aggiunge l'hint al prompt originale per creare un "enhanced teacher prompt". Poi esegue la risposta originale nel nuovo contesto e usa il gap di log probability token-level tra teacher e student come segnale di training direzionale.
Non solo buono o cattivo, ma esattamente cosa cambiare e come. Questo è più ricco di qualsiasi reward scalare. Quando dico a un agente "avresti dovuto leggere il file di config prima di suggerire modifiche", diventa un segnale di apprendimento concreto sull'ordine di utilizzo dei tool.
Scopri i miei progetti
Dai un'occhiata ai progetti su cui sto lavorando e alle tecnologie che utilizzo.
La Realtà Hardware: Questa è Infrastruttura da Ricerca
Prima di entusiasmarti troppo, ecco la dose di realtà: OpenClaw-RL richiede otto GPU di default.
- 4 GPU per il training actor
- 2 GPU per la generazione di rollout
- 2 GPU per il process reward model
Serve anche CUDA 12. Non è qualcosa che puoi far girare su un laptop o un server con una singola GPU. È infrastruttura da ricerca, il tipo di setup che hanno università e laboratori.
Per la maggior parte degli scopi pratici, questo significa che OpenClaw-RL è attualmente sperimentale. A meno che tu non abbia accesso a un cluster multi-GPU, non lo farai girare a casa. Ma capire l'architettura è comunque prezioso - è qui che sta andando lo sviluppo degli agenti.
Setup della Configurazione
Se hai l'hardware, la config di OpenClaw è diretta. Punti il tuo client OpenClaw al server RL che serve un'API compatibile OpenAI sulla porta 30000:
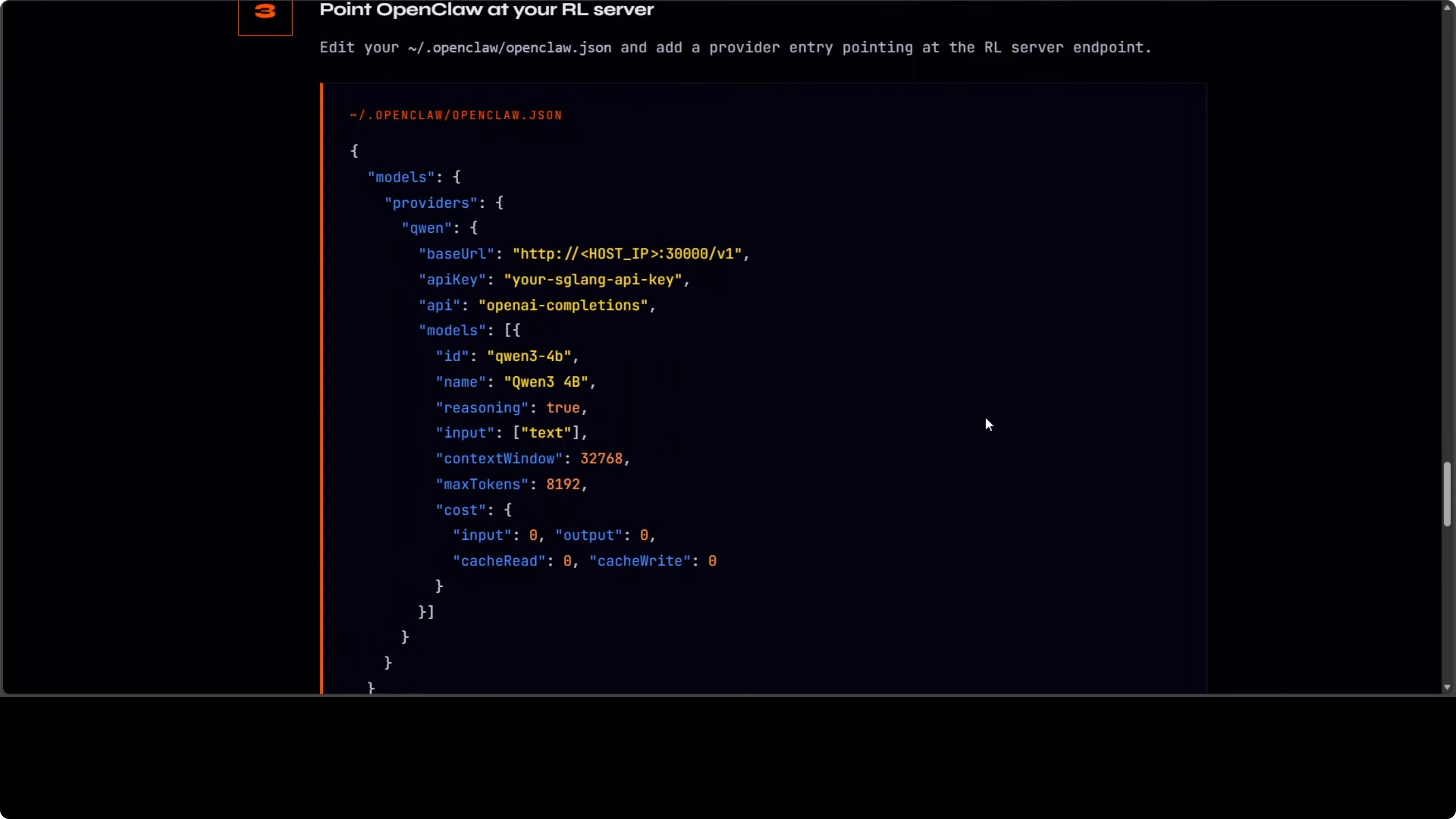
Ecco la config minima:
{
"openai": {
"base_url": "http://localhost:30000/v1",
"api_key": "sk-your-local-key"
}
}Step-by-step:
- Crea o aggiorna il tuo file di config OpenClaw per settare
base_urlahttp://localhost:30000/v1 - Riavvia il client dell'assistente per caricare il nuovo endpoint
- Chatta con l'agente e fornisci feedback mentre il training procede in background
Se hai le otto GPU, vedrai policy, PRM e training engine lavorare mentre continui a chattare. Il loop è continuo e autocontenuto. OpenClaw non sa nemmeno che sta avvenendo il training - riceve solo una risposta.
Roadmap: Due Tracce
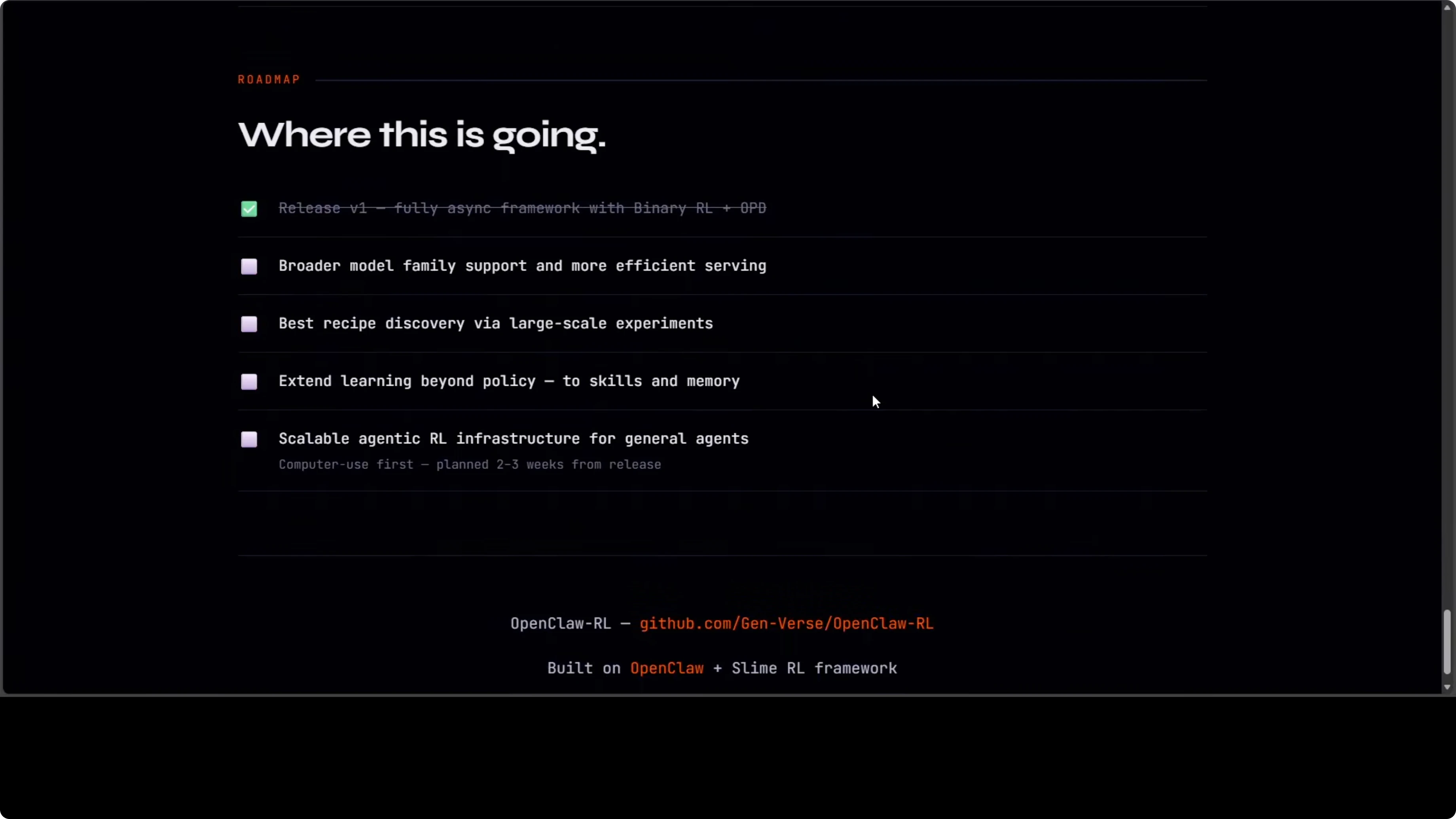
Il progetto ha due linee di sviluppo:
- Ottimizzazione agente personale - Rendere il tuo specifico agente migliore dai tuoi specifici pattern di utilizzo
- Infrastruttura RL agentica generale - Per agenti computer use su larga scala, pianificata per il prossimo release
L'ottimizzazione dell'agente personale è il killer use case. Immagina un assistente che impara che vuoi sempre i PR reviewati prima del merge, o che preferisci spiegazioni dettagliate invece di risposte concise, o che lavori in uno specifico tech stack e vuoi esempi di codice in quel contesto.
Quel tipo di personalizzazione è impossibile con modelli statici. Con OpenClaw-RL, succede automaticamente dall'uso normale.
Vuoi integrare AI nel tuo business?
Contattami per una consulenza su come implementare strumenti AI nella tua azienda.
Perché È Importante
Questo è dove sta andando l'ecosistema OpenClaw: non solo un assistente che risponde, ma un assistente che impara.
La maggior parte degli assistenti AI oggi sono come venditori di enciclopedie - sanno molto, ma non sanno di te. Non ricordano che preferisci TypeScript a JavaScript, che vuoi sempre unit test col codice, che lavori in un dominio specifico con vincoli specifici.
OpenClaw-RL rende l'AI personale davvero personale. Il loop asincrono continuo significa che il modello continua a servire mentre migliora. Nessun downtime per il training, nessun job di fine-tuning manuale, nessun workflow di annotazione costoso.
I requisiti hardware sono alti ora, ma l'architettura è solida. Man mano che i modelli più piccoli migliorano e l'hardware costa meno, questo approccio diventerà pratico per più casi d'uso.
Considerazioni Finali
OpenClaw-RL trasforma conversazioni naturali in segnali di training pratici. Ottieni un modello che si adatta alle tue abitudini sulla tua infrastruttura e migliora senza interrompere il servizio.
La vera innovazione è il loop continuo. L'RL tradizionale richiede di fermare il modello, raccogliere traiettorie, addestrare, poi deployare. OpenClaw-RL fa tutto in live. Chatti, il modello impara, i pesi si aggiornano, il servizio continua.
Se hai accesso all'hardware (o vuoi sperimentare con versioni ridotte), la repo GitHub di OpenClaw-RL è il punto di partenza. Anche se non lo fai girare tu stesso, capire come funziona l'RL guidato da conversazioni sarà prezioso man mano che questo approccio diventa più comune.
Questo è un passo chiaro verso assistenti che imparano davvero nel loop. Non solo rispondere basandosi su un dataset congelato, ma adattarsi al tuo effettivo stile di lavoro dalle tue effettive conversazioni.
È il tipo di strumento AI che voglio.