
Every AI assistant I've used has had one thing in common: it's static. You chat with it today, you chat with it tomorrow, and it's exactly the same. It doesn't learn from your corrections, your preferences, or your way of working.
OpenClaw-RL changes that. It's a reinforcement learning framework that turns your everyday conversations into training signals. You give a thumbs up, a correction, or a concrete instruction like "you should have checked that file first," and the model updates in the background.
This isn't fine-tuning on someone else's dataset. This is your model trained on your conversations on your infrastructure, never leaving your server.
What is OpenClaw-RL?
OpenClaw-RL is a fully asynchronous reinforcement learning framework that adapts to your habits, your preferences, and your working style. Unlike traditional fine-tuning that requires collecting data, annotating it, and running expensive training jobs, OpenClaw-RL learns continuously from your natural interactions.
The key insight: your next message in a conversation is feedback on the previous response. If you correct the agent, clarify something, or just continue the conversation naturally, that's all training signal.
The Architecture: Four Components That Never Block
The system is built around four independent asynchronous components that run in parallel without blocking each other:
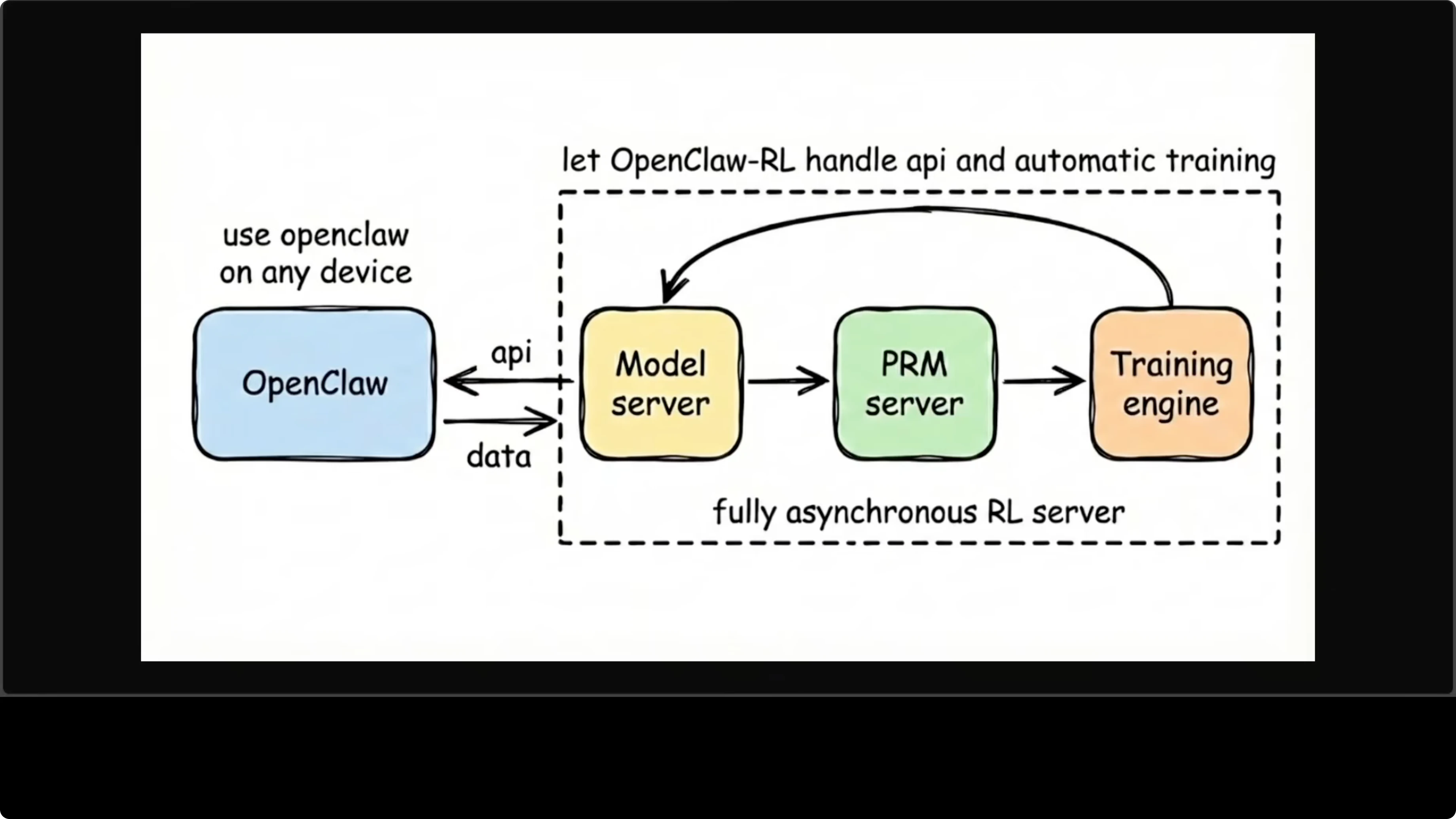
- OpenClaw client - Your assistant running on any device, sends conversations to the model server
- Model server - Serves the live agent as an OpenAI-compatible API on port 30000
- PRM server - A process reward model that evaluates each turn and scores it
- Training engine - Runs gradient updates in the background, pushes weights back to model server
The whole loop is continuous. You're chatting with the agent while it's training, and neither interrupts the other. This is the real innovation - most RL setups require stopping the model to train. OpenClaw-RL keeps serving while improving.
Need help with AI integration?
Get in touch for a consultation on implementing AI tools in your business.
Two Training Methods
OpenClaw-RL supports two approaches to learning from conversation:
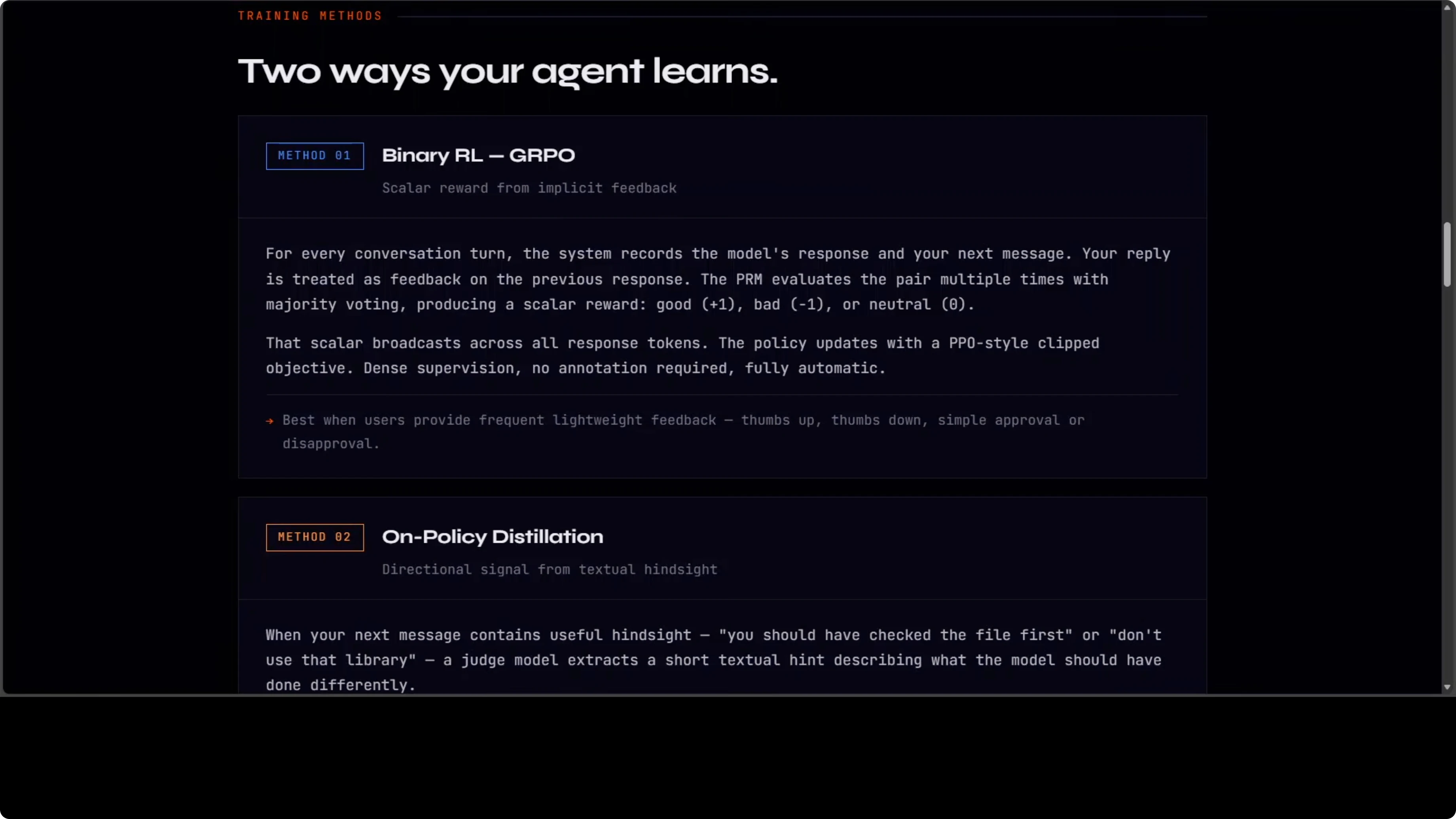
Binary RL (GRPO + PPO)
The first method treats conversation flow as implicit feedback. For every turn, the system records what the model said and what you said next. Your next message is treated as feedback on the previous response.
A process reward model votes on whether that response was good, bad, or neutral. That scalar reward gets broadcast across all response tokens, and the policy updates using a PPO-style clipped objective.
Simple, dense, automatic. No annotation required. Natural chat flow becomes steady learning signals.
Directional Hints
This is the more powerful method when you give explicit feedback. When you tell the model what it should have done differently, a judge model extracts a short textual hint from that feedback.
It appends the hint to the original prompt to create an "enhanced teacher prompt." Then it runs the original response under the enhanced context and uses the token-level log probability gap between teacher and student as a directional training signal.
Not just good or bad, but exactly what to change and how. This is richer than any scalar reward. When I tell an agent "you should have read the config file before suggesting changes," that becomes a concrete learning signal about tool usage order.
Explore my projects
Check out the projects I am working on and the technologies I use.
Hardware Reality: This is Research Infrastructure
Before you get too excited, here's the reality check: OpenClaw-RL requires eight GPUs by default.
- 4 GPUs for the training actor
- 2 GPUs for rollout generation
- 2 GPUs for the process reward model
You also need CUDA 12. This is not something you run on a laptop or a single-GPU server. This is research infrastructure, the kind of setup universities and research labs have.
For most practical purposes, this means OpenClaw-RL is currently experimental. Unless you have access to a multi-GPU cluster, you're not running this at home. But understanding the architecture is valuable - this is where agent development is heading.
Configuration Setup
If you do have the hardware, the OpenClaw config is straightforward. You point your OpenClaw client to the RL server serving an OpenAI-compatible API on port 30000:
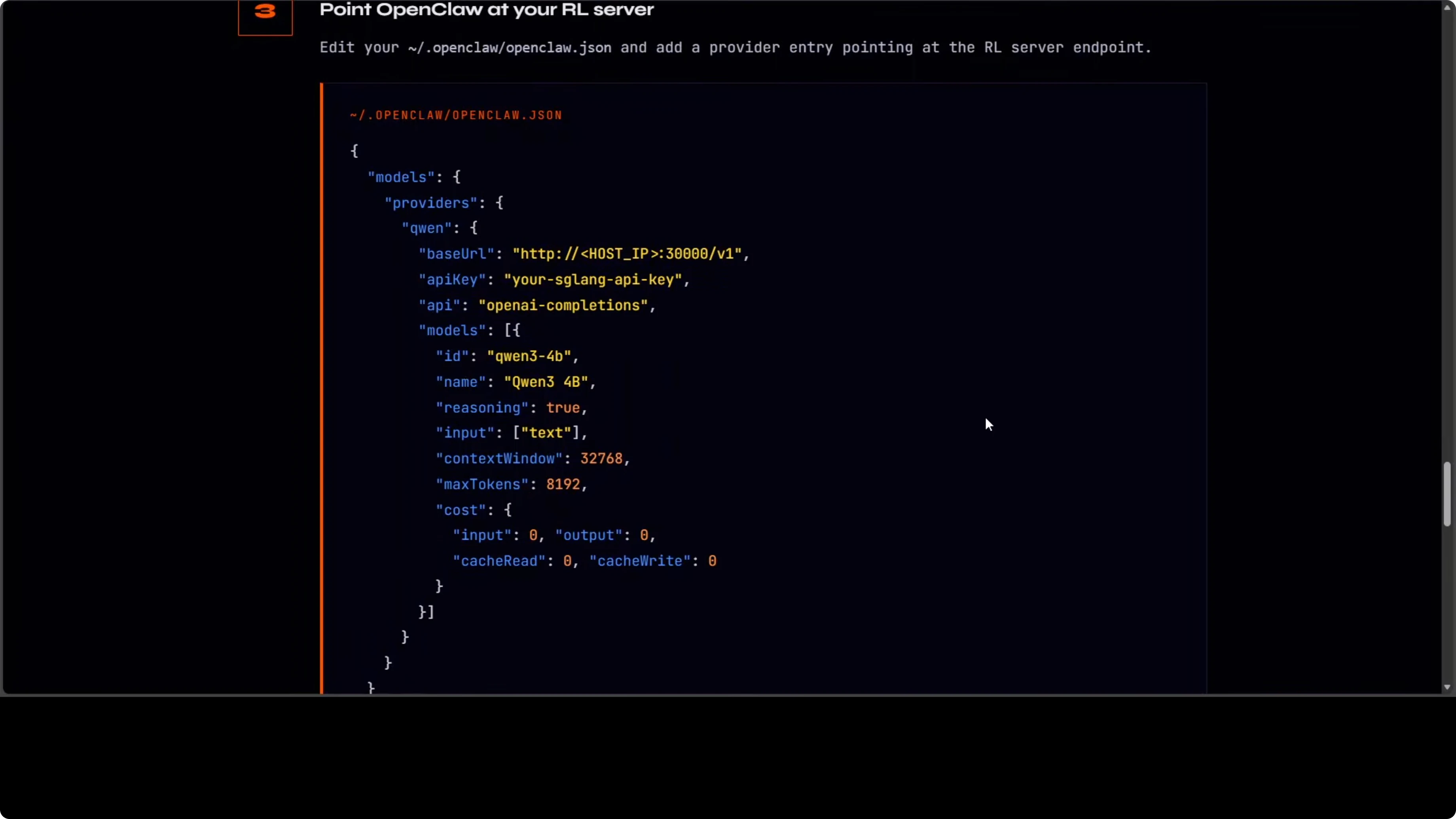
Here's the minimal config:
{
"openai": {
"base_url": "http://localhost:30000/v1",
"api_key": "sk-your-local-key"
}
}Step-by-step:
- Create or update your OpenClaw config file to set
base_urltohttp://localhost:30000/v1 - Restart your assistant client to pick up the new endpoint
- Chat with the agent and provide feedback while training proceeds in the background
If you have the eight GPUs, you'll see the policy, PRM, and training engine working while you continue chatting. The loop is continuous and self-contained. OpenClaw never knows training is happening - it just gets a response.
Roadmap: Two Tracks
The project has two development tracks:
- Personal agent optimization - Making your specific agent better from your specific usage patterns
- General agentic RL infrastructure - For computer use agents at scale, planned for the next release
The personal agent optimization is the killer use case. Imagine an assistant that learns you always want PRs reviewed before merging, or that you prefer detailed explanations over terse responses, or that you work in a specific tech stack and want code examples in that context.
That kind of personalization is impossible with static models. With OpenClaw-RL, it happens automatically from normal usage.
Want to integrate AI in your business?
Contact me for a consultation on implementing AI tools in your company.
Why This Matters
This is where the OpenClaw ecosystem is heading: not just an assistant that responds, but an assistant that learns.
Most AI assistants today are like encyclopedia salespeople - they know a lot, but they don't know you. They don't remember that you prefer TypeScript over JavaScript, that you always want unit tests with code, that you work in a specific domain with specific constraints.
OpenClaw-RL makes personal AI actually personal. The continuous asynchronous loop means the model keeps serving while improving. No downtime for training, no manual fine-tuning jobs, no expensive annotation workflows.
The hardware requirements are steep right now, but the architecture is sound. As smaller models get better and hardware gets cheaper, this approach will become practical for more use cases.
Final Thoughts
OpenClaw-RL turns natural conversation into practical training signals. You get a model that adapts to your habits on your own infrastructure and improves without interrupting service.
The real innovation is the continuous loop. Traditional RL requires stopping the model, collecting trajectories, training, then deploying. OpenClaw-RL does it all live. You chat, the model learns, weights update, service continues.
If you have access to the hardware (or want to experiment with scaled-down versions), the OpenClaw-RL GitHub repo is the place to start. Even if you don't run it yourself, understanding how conversation-driven RL works will be valuable as this approach becomes more common.
This is a clear step toward assistants that truly learn in the loop. Not just responding based on a frozen dataset, but adapting to your actual working style from your actual conversations.
That's the kind of AI tool I want.
