
Se vuoi una pipeline funzionante di trascrizione QVAC + Whisper su macOS oggi, puoi averla in circa dieci minuti. Installi @qvac/sdk, carichi un modello Whisper, gli passi un file .wav, ti torna una stringa. Niente cloud, niente API key, niente fatturazione al minuto, niente audio che esce dal laptop. Tutto sta in venti righe.
Quella è la demo. Il motivo per cui dovresti farlo davvero è più difficile da mettere in una slide: nel momento in cui infili la trascrizione cloud in un prodotto reale, inizi a scrivere review sulla privacy. Registrazioni di meeting, voice note, chiamate clienti, interviste interne - diventa tutto "dati che mandiamo a un vendor". Un Whisper locale che gira tramite QVAC SDK spegne quella conversazione. L'audio non lascia mai il disco su cui è stato registrato.
Questo tutorial percorre il loop end-to-end. Genererai un sample con il say di macOS, lo trascriverai con WHISPER_TINY, passerai a un modello English-only più grande per più accuratezza, farai benchmark su entrambi, e poi impacchetterai il tutto come una CLI transcribe <file> da mettere in ~/bin. Tutto quello che vedi qui è stato prodotto eseguendo davvero il codice su un Mac il 2026-04-26 - i transcript, i tempi e gli output che vedrai sono reali.
Perché fare trascrizione offline su macOS?
Tre motivi che si sommano:
- Privacy. Le API cloud vedono ogni byte che carichi. Per qualunque cosa coperta da NDA, GDPR, HIPAA, o anche solo "il legal preferirebbe di no", la risposta più sicura è non mettere mai il file sul server di qualcun altro. Con un Whisper locale, il file audio passa da disco → memoria → testo e non lascia mai la macchina.
- Costo.
whisper-1di OpenAI costa $0,006/minuto. È nulla per un singolo file e sorprendentemente concreto per un'app che trascrive mille chiamate clienti a settimana. Whisper locale è gratis a runtime; paghi una volta in banda di download e in spazio su disco. - Latency. Il round-trip verso un'API di trascrizione cloud sono centinaia di millisecondi prima ancora che inizi qualunque lavoro reale. Whisper locale su Apple Silicon trascrive un clip da 30 secondi in ~400 ms, model load incluso. Per use case interattivi - voice note, riassunti di meeting, sottotitoli live - quel gap è la differenza tra "sembra istantaneo" e "sembra rotto".
QVAC SDK è il modo più pulito di mettere insieme questa cosa da JavaScript. Se vuoi il pitch più ampio, l'ho coperto in Cos'è il QVAC SDK? - la versione corta è che lo stesso shape loadModel → fai la cosa → unloadModel funziona per trascrizione, LLM, generazione di immagini e altre sei modalità. Questo post è il deep dive sul ramo della trascrizione.
Prerequisiti
Ti serviranno:
- macOS 14+ con Apple Silicon (accelerazione Metal). I Mac Intel funzionano CPU-only e saranno più lenti.
- Node.js ≥ 22.17. Versioni più vecchie crashano a runtime quando chiami
loadModel(). - ~500 MB di disco libero per SDK + binari nativi + un piccolo modello Whisper.
- Una connessione internet funzionante solo per il primo run - i modelli si scaricano una volta e vengono cachati in
~/.qvac/models/.
Niente configurazione GPU, niente cmake, niente virtualenv Python. I binari nativi di QVAC (whispercpp-transcription, in questo caso il fork di whisper.cpp) sono dentro al pacchetto npm.
Prepara il sandbox di trascrizione QVAC SDK
Tre comandi:
mkdir qvac-whisper-test && cd qvac-whisper-test
npm init -y
npm install @qvac/sdkL'install tira dentro circa 200 pacchetti e all'incirca 2,6 GB di binari nativi (che coprono tutti gli engine di QVAC: Whisper, llama.cpp, stable-diffusion.cpp, ONNX Runtime, Bergamot). Sul mio Mac ha impiegato poco meno di tre minuti su connessione cablata.
Se ti serve solo la trascrizione e il footprint dei binari conta - per un'app Electron, ad esempio - più avanti puoi usare qvac bundle sdk per shippare solo gli engine che chiami davvero. Per questo tutorial lasciamo il bundle completo; al sandbox di sviluppo non interessa.
Ti serve anche un file audio. Salta la parte in cui vai a caccia di un podcast di pubblico dominio e generane uno con il comando say integrato di macOS, che produce WAV direttamente:
say -v Samantha --data-format=LEI16@16000 -o sample.wav \
"QVAC SDK runs Whisper transcription locally on your Mac. The quick brown fox jumps over the lazy dog."Il flag --data-format=LEI16@16000 sta lavorando sul serio: chiede PCM little-endian a 16 bit a 16 kHz, che è esattamente quello che vuole Whisper. Se lo salti, say di default produce AIFF a 22 kHz e l'FFmpeg interno di QVAC ti farà il resample - ma è più veloce dare a Whisper il formato che preferisce in partenza.
Step 1: Hello-world di trascrizione con WHISPER_TINY
Salva questo come 01-hello.mjs:
import {
loadModel,
transcribe,
unloadModel,
WHISPER_TINY,
} from "@qvac/sdk"
console.log("Loading WHISPER_TINY...")
const modelId = await loadModel({
modelSrc: WHISPER_TINY,
modelType: "whispercpp-transcription",
onProgress: ({ percentage }) => {
if (percentage !== undefined) {
process.stdout.write(`\rDownloading: ${Math.round(percentage)}% `)
}
},
})
process.stdout.write("\n")
console.log("Transcribing sample.wav...")
const text = await transcribe({
modelId,
audioChunk: "./sample.wav",
})
console.log("\n--- Transcript ---")
console.log(text)
console.log("------------------")
await unloadModel({ modelId })
console.log("Done.")Tre cose da notare:
WHISPER_TINYnon è una stringa. È una costante tipata dal model registry di QVAC che impacchetta source URL, dimensione attesa (~74 MB), checksum SHA-256 e metadati dell'engine. Il type-checking prende i typo prima che diventino errori a runtime.modelTypeaccetta due forme. Il nome canonico dell'engine è"whispercpp-transcription"- è quello che vedi nei log dell'SDK ed è quello chedist/schemas/model-types.jschiama literal canonica. L'alias più corto"whisper"risolve alla stessa cosa tramite la mappaModelTypeAliasesintegrata nell'SDK ed è quello che usano la maggior parte delle docs e degli snippet del blog QVAC. In questo post resto sulla forma canonica così che il confine dell'engine sia visibile, mamodelType: "whisper"è identico a runtime. Il set completo di alias dentro l'SDK:llm,whisper,embeddings,nmt,parakeet,tts,ocr,diffusion.audioChunkè un nome fuorviante. Accetta sia un path di un file sia unBuffer, non solo un chunk di audio. Il path è la via più semplice per file locali.
Eseguilo:
node 01-hello.mjs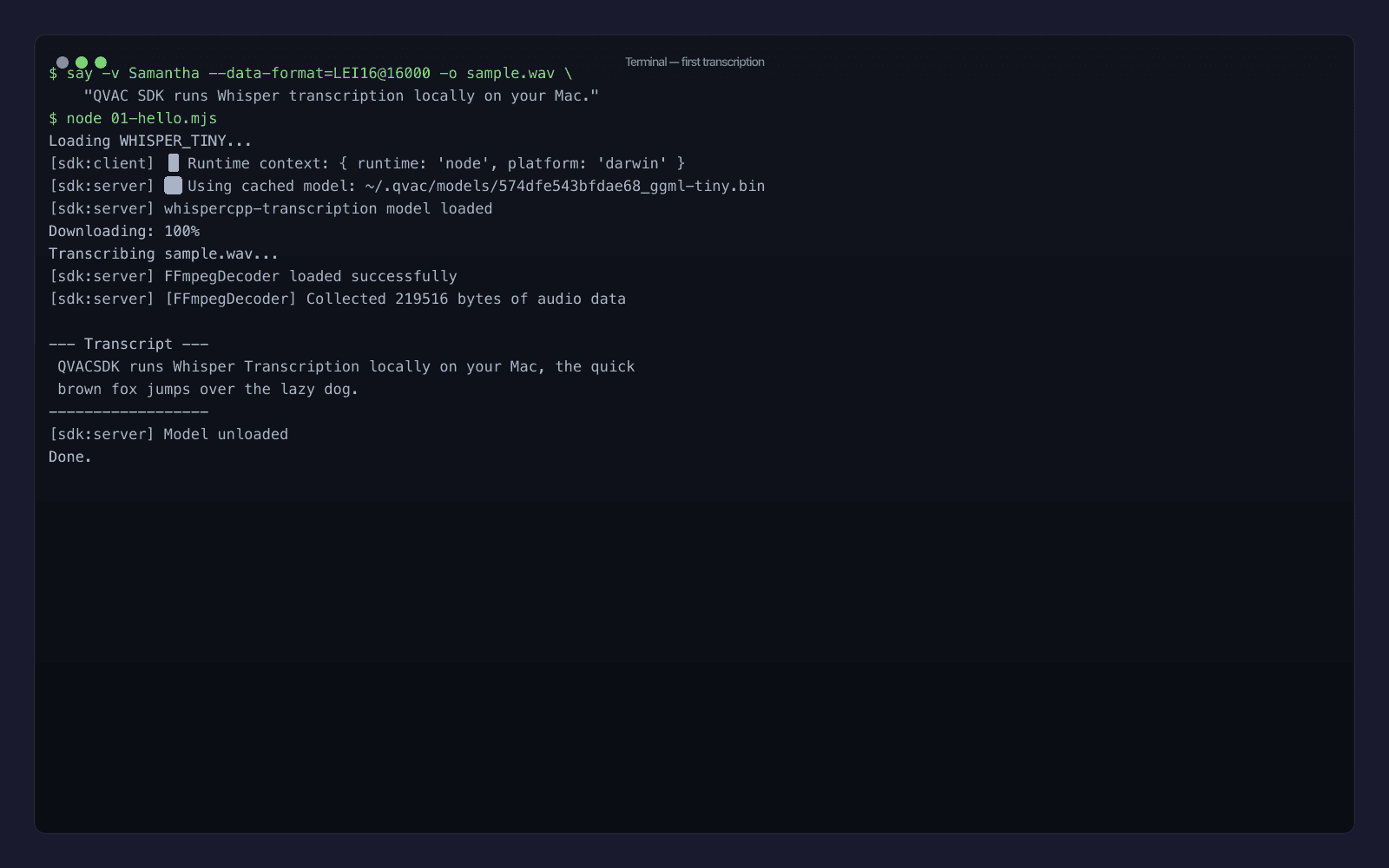
Al primo passaggio, il modello si scarica dal registry peer-to-peer di QVAC e viene cachato in ~/.qvac/models/. Il secondo run è caricamento istantaneo. Il transcript sulla mia macchina:
QVACSDK runs Whisper Transcription locally on your Mac, the quick brown fox jumps over the lazy dog.
Nota che WHISPER_TINY legge "QVAC SDK" tutto attaccato come QVACSDK - il tokenizer non conosce il brand, e il modello tiny non ha abbastanza contesto per indovinare. È esattamente il tipo di piccola imprecisione che ti spinge a fare upgrade del modello o a passare un prompt: per orientare l'output verso il vocabolario giusto. La chiamata transcribe() accetta proprio un parametro opzionale prompt.
Step 2: Benchmark WHISPER_TINY vs WHISPER_EN_BASE su un audio più lungo
Tiny è ottimo per una demo veloce. Per qualunque cosa che spedirai davvero in produzione, vuoi un benchmark onesto su audio realistico. Generiamo un clip più lungo - un finto intro di podcast da circa 35 secondi:
say -v Samantha --data-format=LEI16@16000 -o podcast.wav \
"Welcome to the local AI podcast. Today we are talking about running large language models on your own laptop. The big idea is that you no longer need to send your private documents to a cloud provider. With tools like Whisper and Llama, you can transcribe audio, generate text, and translate languages entirely offline. Let us see how it works in practice."Poi scrivi 03-benchmark.mjs:
import {
loadModel,
transcribe,
unloadModel,
WHISPER_TINY,
WHISPER_EN_BASE_Q8_0,
} from "@qvac/sdk"
const audioFile = "./podcast.wav"
async function bench(modelSrc, label) {
const t0 = performance.now()
const modelId = await loadModel({
modelSrc,
modelType: "whispercpp-transcription",
})
const tLoaded = performance.now()
const text = await transcribe({ modelId, audioChunk: audioFile })
const tTranscribed = performance.now()
await unloadModel({ modelId })
console.log(`\n[${label}]`)
console.log(`load: ${(tLoaded - t0).toFixed(0)} ms`)
console.log(`transcribe: ${(tTranscribed - tLoaded).toFixed(0)} ms`)
console.log(`text: ${text.trim()}`)
}
await bench(WHISPER_TINY, "WHISPER_TINY (multilingual, 75 MB)")
await bench(WHISPER_EN_BASE_Q8_0, "WHISPER_EN_BASE_Q8_0 (English, 62 MB, Q8)")Eseguilo:
node 03-benchmark.mjs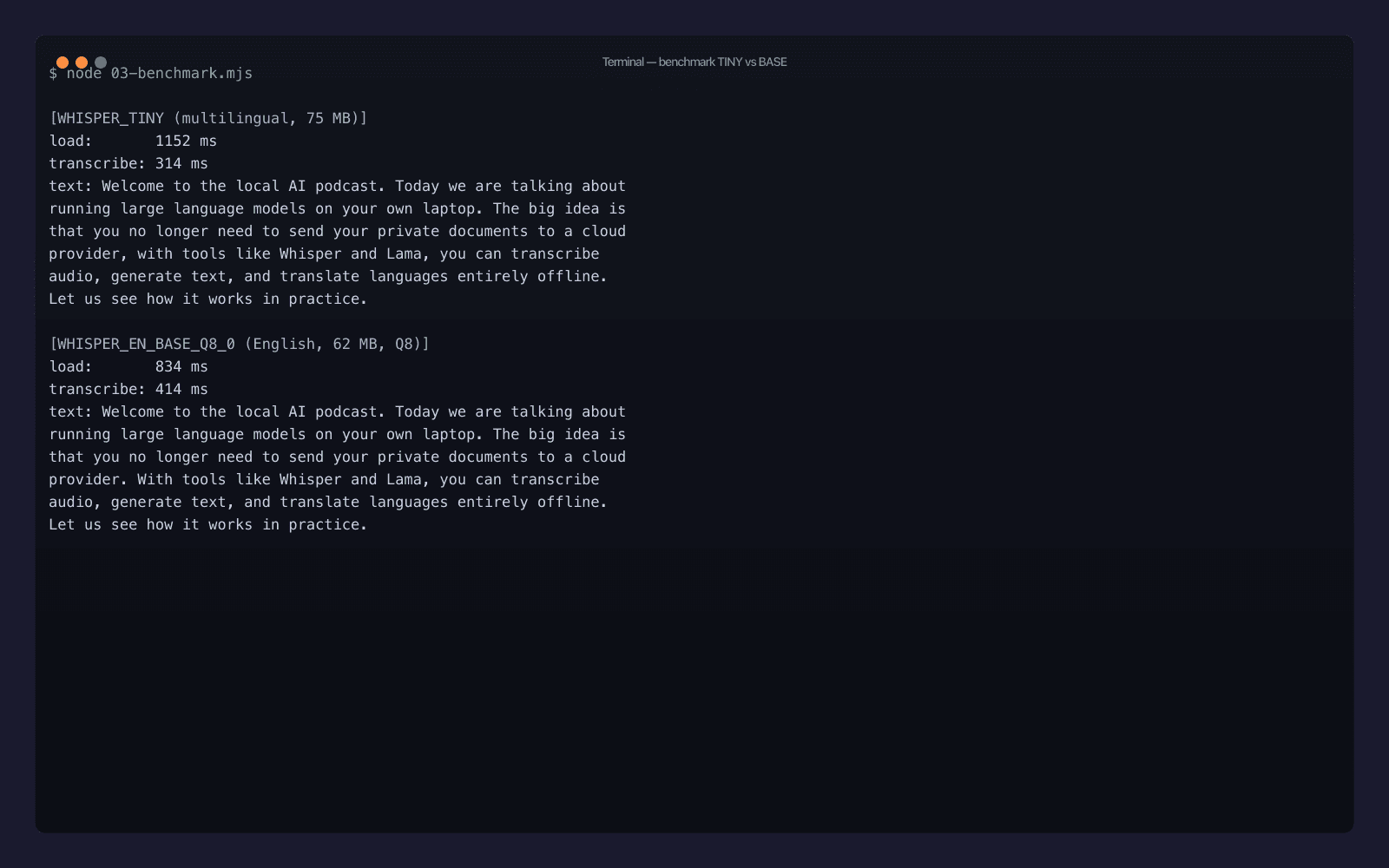
Numeri reali dal mio Mac, dopo il secondo run (così il caricamento del modello è da disco, non da rete):
| Modello | Dimensione | Load | Transcribe (clip 35 s) | Real-time factor |
|---|---|---|---|---|
WHISPER_TINY | 75 MB | 1152 ms | 314 ms | ~111× |
WHISPER_EN_BASE_Q8_0 | 62 MB | 834 ms | 414 ms | ~85× |
Cose che vale la pena notare:
- Entrambi i transcript sono praticamente perfetti su una voce pulita - l'unico errore è "Llama" → "Lama", che è un problema del tokenizer, non del modello. Un singolo
prompt: "Llama, GGUF, QVAC, Whisper"lo risolve per i run di produzione. - Il modello English-only quantizzato a Q8 è più piccolo e più veloce da caricare del tiny multilingual, pur stando un gradino più su nella scala dell'accuratezza. La quantizzazione sta lavorando per davvero.
- La differenza di accuratezza si vede nella punteggiatura, non nelle parole.
WHISPER_EN_BASE_Q8_0chiude la seconda frase con un punto;WHISPER_TINYla prosegue con una virgola. Per qualunque cosa che mostrerai a un essere umano, conta. - ~110× di real-time factor significa che la registrazione di un meeting da 1 ora si trascrive in circa 32 secondi. Non è un refuso.
Regola pratica per la produzione: spedisci WHISPER_EN_BASE_Q8_0 per app English-only, spedisci WHISPER_TINY se ti serve una piccola default multilingual, e tira fuori WHISPER_LARGE_V3_TURBO (anche lui nel registry) solo quando l'accuratezza è la metrica critica e non ti dispiace un modello da ~1,5 GB su disco.
Hai bisogno di aiuto con l'integrazione AI?
Contattami per una consulenza sull'implementazione di AI locale e privata nel tuo prodotto.
Step 3: Trasforma QVAC + Whisper in una CLI
Lo script di benchmark va bene come benchmark. Quello che vuoi davvero è uno strumento che puoi lanciare su qualunque file audio. Salva questo come transcribe.mjs:
#!/usr/bin/env node
import {
loadModel,
transcribe,
unloadModel,
WHISPER_TINY,
WHISPER_EN_BASE_Q8_0,
} from "@qvac/sdk"
import { existsSync } from "node:fs"
const file = process.argv[2]
const flag = process.argv[3] ?? "--fast"
if (!file) {
console.error("usage: transcribe <file.wav> [--fast | --accurate]")
process.exit(1)
}
if (!existsSync(file)) {
console.error(`error: ${file} not found`)
process.exit(1)
}
const modelSrc = flag === "--accurate" ? WHISPER_EN_BASE_Q8_0 : WHISPER_TINY
const modelId = await loadModel({
modelSrc,
modelType: "whispercpp-transcription",
})
const text = await transcribe({ modelId, audioChunk: file })
await unloadModel({ modelId })
console.log(text.trim())Rendilo eseguibile e lancialo:
chmod +x transcribe.mjs
./transcribe.mjs podcast.wav --accurate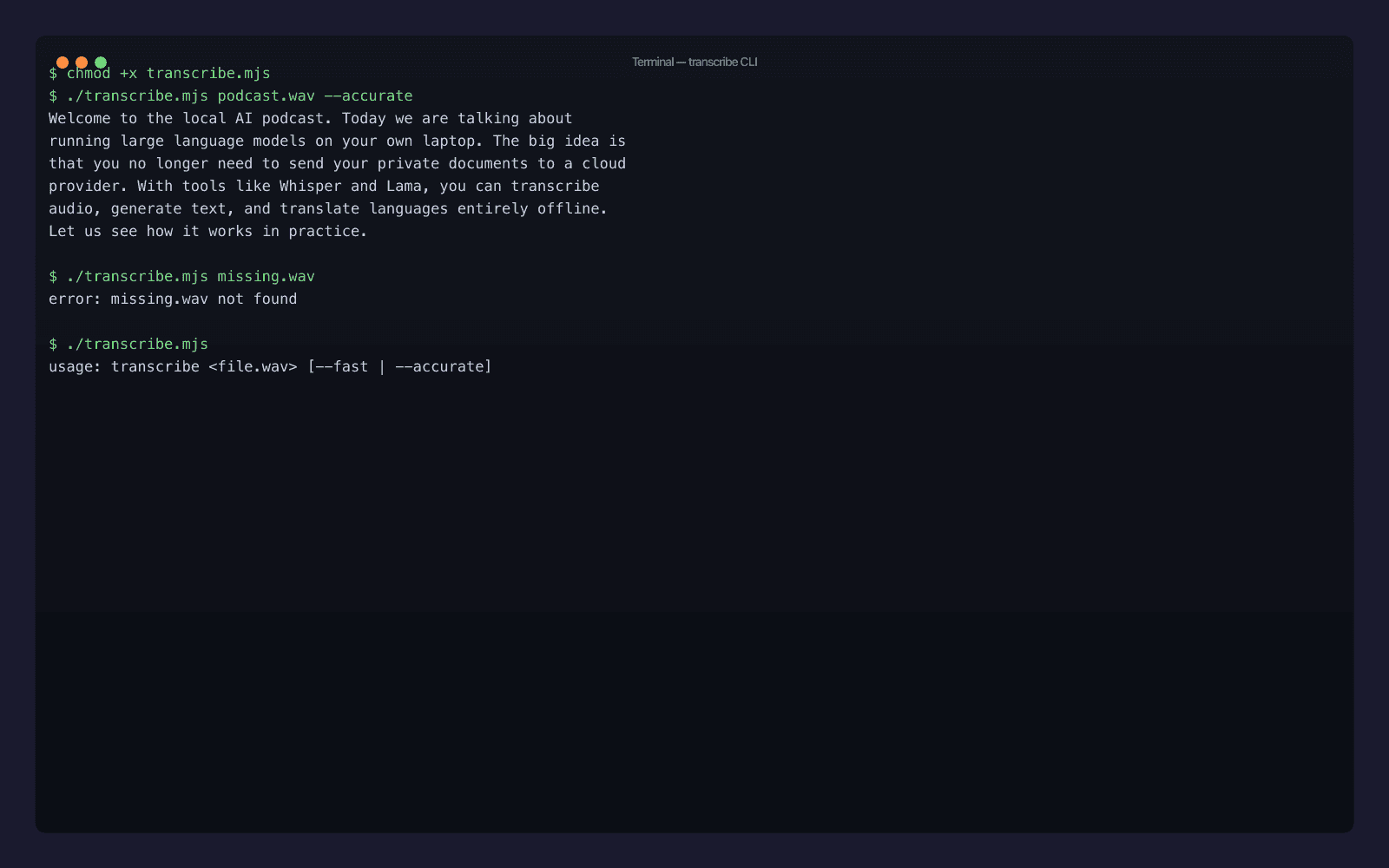
L'output completo:
Welcome to the local AI podcast. Today we are talking about running large language models on your own laptop. The big idea is that you no longer need to send your private documents to a cloud provider. With tools like Whisper and Lama, you can transcribe audio, generate text, and translate languages entirely offline. Let us see how it works in practice.
Venticinque righe contando import e gestione errori, e hai uno strumento privato di speech-to-text che gira offline per sempre. Mettilo in symlink in ~/bin/transcribe e hai finito - transcribe meeting.wav --accurate > notes.md è ora un workflow reale sulla tua macchina.
Qualche idea di production polish che il file lascia fuori (di proposito, per restare corti):
- Streaming. Sostituisci
transcribe()contranscribeStream()per ricevere il testo a chunk man mano che il voice activity detector di Whisper trova i confini dei segmenti. Utile per file lunghi in cui vuoi mostrare il progresso. - Diarization. Se ti serve "chi ha detto cosa", passa al plugin Parakeet (
@qvac/sdk/parakeet-transcription/plugin) - stesso shape diloadModel,modelTypediverso, e il risultato include le label degli speaker. - Input non-WAV. Il decoder FFmpeg interno di QVAC (lo vedi nei log come
FFmpegDecoder) accetta MP3, MP4, M4A, OGG, FLAC. Passagli il path; al formato ci pensa lui. - Daemon long-running. Tieni un
loadModelcaldo in un processo padre e accetta path su un Unix socket. L'SDK attuale fa già girare Whisper in un Bare worker - il modello resta caricato attraverso multiple chiamatetranscribe()nello stesso processo.
Risolvere problemi di trascrizione QVAC + Whisper su macOS
Sulla mia macchina la happy path era pulita. Ecco le failure mode più probabili sulla tua, con il fix reale:
Cannot find module '@qvac/sdk'dopo l'install. Probabilmente sei su Node ≤ 22.16. Lancianode --versione fai upgrade. L'SDK usa feature dei worker thread native arrivate in 22.17. Non c'è fallback - Node più vecchio crasha al momento dell'import, prima ancora di arrivare aloadModel().- Il download del modello si blocca a 0%. Il registry di default tira giù i modelli peer-to-peer via Hyperswarm. Se sei dietro un firewall aziendale che blocca UDP, lo swarm non si forma. O configuri
swarmRelaysin unqvac.config.ts(l'SDK ha supporto built-in di blind relay per il NAT/firewall traversal) o settiQVAC_REGISTRY_HTTP_FALLBACK=1per forzare i fetch HTTP-only. - Transcript vuoto o di un singolo carattere. Il tuo audio ha probabilmente la sample rate sbagliata. Whisper si aspetta 16 kHz; l'FFmpeg interno dell'SDK ti fa il resample, ma se l'input è corrotto (header WAV troncato, file di lunghezza zero) produce spazzatura. Lancia
file your-audio.wavper confermare che è un WAVE vero, effprobe -i your-audio.wavper ispezionare canali e sample rate. - La prima chiamata richiede minuti, la seconda è istantanea. È atteso. Il primo run scarica i pesi in
~/.qvac/models/e valida il checksum SHA-256. I run successivi colpiscono la cache locale. Per pre-warm di un modello senza trascrivere nulla, chiamaloadModel()e poiunloadModel()in uno script di setup.
Se vedi qualcos'altro, l'SDK espone getLogger() e un helper loggingStream() - alzare il livello a debug ti mostra ogni chiamata dentro al Bare worker, e di solito basta a localizzare il problema.
Cosa hai costruito alla fine
Se hai eseguito ogni blocco di questo post end-to-end, hai:
- Un'install di
@qvac/sdk, più~/.qvac/models/popolato con i pesi GGUF diWHISPER_TINYeWHISPER_EN_BASE_Q8_0. - Un
01-hello.mjsche dimostra che il loop minimaleloadModel → transcribe → unloadModelgira su questa macchina. - Un
03-benchmark.mjsche ti dà numeri onesti per entrambi i modelli sul tuo hardware. - Una CLI
transcribe.mjsche puoi usare per lavoro vero, oggi, su qualunque file audio.
Tempo totale da npm init alla CLI funzionante su una macchina vergine: dieci minuti se hai banda per l'install dell'SDK, meno di due se non ce l'hai. Costo di runtime in avanti: zero. Chiamate cloud totali: zero. Byte di audio mandati a una terza parte: zero.
Dove andare adesso
Se vuoi più profondità su QVAC sulle capability adiacenti, ti punterei a:
- Le docs ufficiali di QVAC - reference API completa, matrice dei plugin e la lista del model registry (~653 modelli a v0.9).
- Il sorgente di QVAC su GitHub - l'SDK è Apache-2.0 e gli engine C++ (il fork di Whisper sta in
qvac-ext-lib-whisper.cpp) sono tutti lì. - Il mio post più ampio sullo shift dai chatbot agli agenti - quando hai la trascrizione locale che funziona, ti viene voglia di collegarla a qualcosa di più grande, e quel pezzo copre cosa significa "più grande" nel 2026.
Nelle prossime settimane scriverò altro su questa serie: un confronto testa-a-testa contro Ollama per gli LLM locali, un build reale di RAG on-device, la guida iPhone-via-Expo. Se c'è un angolo QVAC che vuoi vedere coperto dopo, scrivimi.
Scopri i miei progetti
Dai un'occhiata ai progetti su cui sto lavorando e alle tecnologie che uso.