
Ho installato e configurato Qwen 3.5 0.8B con OpenClaw e Ollama su Ubuntu, tutto su CPU. Nessuna GPU coinvolta. Il modello pesa circa 1 GB e risponde via Telegram in pochi secondi.
Se stai cercando un modello piccolo, veloce e completamente locale, questa guida ti mostra come integrare Qwen 3.5 0.8B con OpenClaw. Il setup funziona su qualsiasi macchina recente con CPU decente, ideale per test, sviluppo o deployment su VPS economici.
Perché Qwen 3.5 0.8B
800 milioni di parametri. Non è un gigante come GPT-4 o Claude, ma per molti use case va più che bene:
- Risposte rapide su domande semplici
- Assistente Telegram per comandi base
- Prototipazione e test di agenti AI
- Deploy su macchine senza GPU (VPS, Raspberry Pi 5, vecchi laptop)
Il modello è della famiglia Qwen di Alibaba, rilasciato a inizio 2026. Supporta contesto fino a 32k token (circa 24.000 parole), ragionamento multilingue decente (italiano incluso), e inferenza veloce su CPU grazie alla dimensione ridotta.
Caso d'uso reale: l'ho installato sul mio Mac Mini M4 per gestire un bot Telegram di testing che risponde a domande base sulla documentazione di OpenClaw. Non serve per ragionamento complesso, ma per query semplici è veloce e costa zero.
Vuoi integrare AI nel tuo business?
Contattami per una consulenza su come implementare strumenti AI nella tua azienda.
Prerequisiti
Prima di iniziare, assicurati di avere:
- Ollama installato e aggiornato - controlla la versione con
ollama --version - Ubuntu o macOS - la guida è testata su Ubuntu 24.04, ma funziona su qualsiasi distro recente e su Mac
- Almeno 2 GB di RAM libera - il modello occupa circa 1 GB, OpenClaw e Ollama ne aggiungono altri 500 MB
- Node.js 18+ - richiesto da OpenClaw
Se non hai Ollama, installalo da ollama.com. Su Ubuntu:
curl -fsSL https://ollama.com/install.sh | shVerifica l'installazione:
ollama --version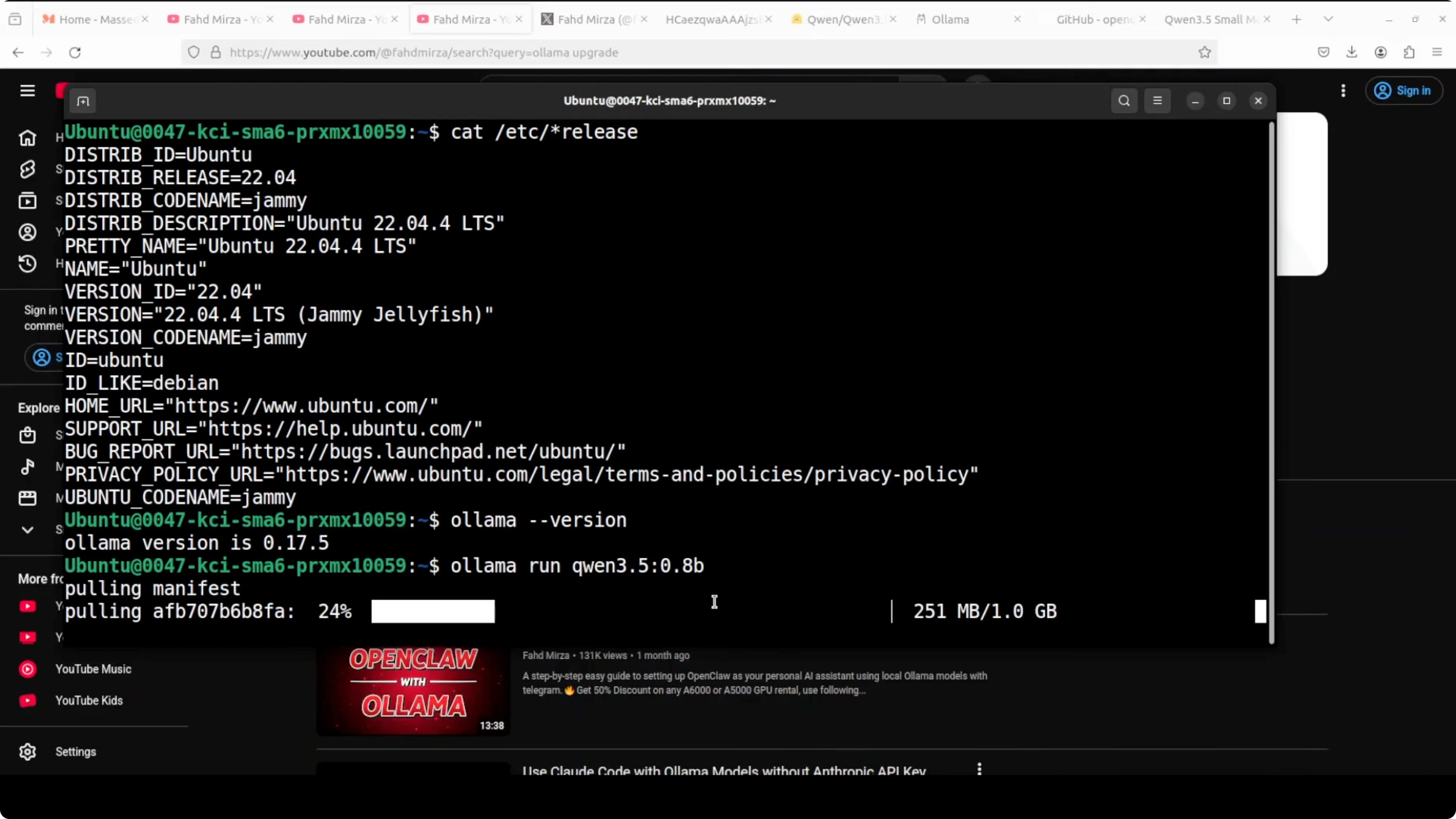
Scaricare e Testare Qwen 3.5 0.8B
Usa Ollama per scaricare il modello. Il tag esatto è qwen3.5:0.8b:
ollama pull qwen3.5:0.8bOllama scarica il modello, verifica il checksum, e lo rende disponibile per inferenza locale. Ci vogliono 1-2 minuti su una connessione decente.
Testa subito il modello in modalità interattiva:
ollama run qwen3.5:0.8bScrivi una domanda base per verificare che funzioni:
>>> Chi ha scritto "I promessi sposi"?
Se ricevi una risposta sensata (Alessandro Manzoni), il modello è attivo. Esci con /bye o Ctrl+D.
Verifica che il modello sia nella lista locale:
ollama listDovresti vedere qwen3.5:0.8b nell'output. Annota il nome esatto - lo userai nella configurazione di OpenClaw.
Scopri i miei progetti
Dai un occhio ai progetti su cui sto lavorando e alle tecnologie che utilizzo.
Installare o Aggiornare OpenClaw
Se hai già OpenClaw installato, aggiornalo alla versione più recente:
npm install -g openclaw@latestSe è la prima installazione, vai su github.com/openclaw/openclaw e segui le istruzioni ufficiali. L'installer prepara l'ambiente, installa le dipendenze e configura il gateway.
L'installazione può richiedere qualche minuto per scaricare aggiornamenti e plugin. Una volta completata, verifica lo stato:
openclaw statusSe vedi "Gateway: running", sei pronto. Se il gateway non è attivo, avvialo manualmente:
openclaw gateway startConfigurare OpenClaw per Ollama
Apri il file di configurazione di OpenClaw:
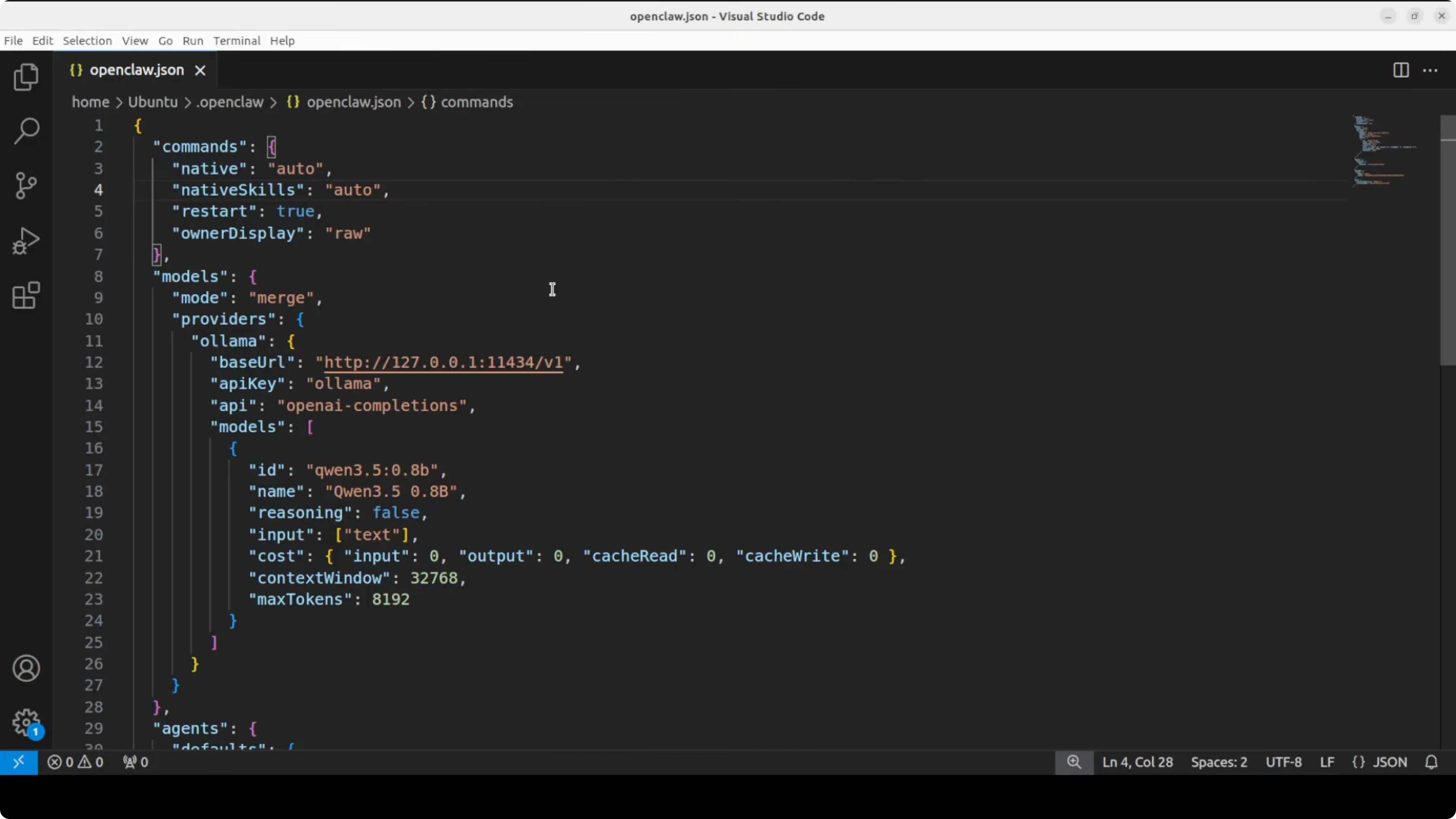
nano ~/.config/openclaw/config.yamlAggiungi o modifica la sezione providers per puntare a Ollama locale e specifica il modello:
gateway:
host: 127.0.0.1
port: 3000
providers:
ollama:
type: ollama
base_url: http://localhost:11434
model: qwen3.5:0.8b
agents:
default:
provider: ollama
system_prompt: Sei un assistente utile.
channels:
telegram:
bot_token: IL_TUO_TOKEN_TELEGRAMPunti chiave:
base_url: http://localhost:11434- endpoint locale di Ollama (porta di default)model: qwen3.5:0.8b- deve corrispondere ESATTAMENTE al nome inollama listprovider: ollama- dice a OpenClaw di usare il provider Ollama locale
Salva il file (Ctrl+O, Enter, Ctrl+X su nano).
Riavvia il gateway per applicare le modifiche:
openclaw gateway restart
Vuoi automatizzare il tuo workflow con AI?
Parliamo di come costruire agenti AI personalizzati per la tua azienda.
Configurare Telegram
Apri Telegram e cerca @BotFather. Avvia una chat e crea un nuovo bot:
/newbot
Segui le istruzioni:
- Scegli un nome per il bot (es. "Qwen Assistant")
- Scegli uno username univoco che termina con
bot(es.qwen_assistant_bot)
BotFather ti darà un token API. Copialo - è lungo, inizia con numeri e contiene il carattere :.
Importante: ruota il token dopo i test se lo esponi in repository pubblici o screenshot.
Ora aggiungi il token al file di configurazione di OpenClaw (lo abbiamo già preparato sopra nella sezione channels.telegram.bot_token). Se preferisci usare il wizard interattivo:
openclaw configureSeleziona:
- Gateway type:
local - Channel:
telegram - Incolla il token quando richiesto
Salva e riavvia il gateway:
openclaw gateway restartTestare il Modello Locale
Avvia l'interfaccia terminale di OpenClaw:
openclaw tuiOppure usa la dashboard web se preferisci:
openclaw dashboardLa dashboard si apre su http://localhost:3000. Se vedi "Unauthorized", genera un token di accesso con openclaw token create e usalo per autenticarti.
Per accoppiare Telegram, vai su Telegram e cerca il bot che hai creato (lo trovi cercando lo username che hai scelto, es. @qwen_assistant_bot). Clicca /start.
Se tutto è configurato correttamente, il bot risponderà immediatamente usando il modello Qwen 3.5 0.8B locale via Ollama.
Test pratico: invia un messaggio semplice come:
Ciao! Come funzioni?
Dovresti ricevere una risposta in pochi secondi. La risposta arriva sia nell'interfaccia terminale/dashboard di OpenClaw che direttamente su Telegram.
Verifica latenza: su un Mac Mini M4 con CPU M4, la latenza media è di 2-3 secondi per risposta (dipende dalla complessità della query). Su un VPS con CPU Intel Xeon, conta 5-8 secondi.
Hai domande su OpenClaw?
Scrivimi per consulenze tecniche su setup, deployment e ottimizzazione di agenti AI.
Limitazioni e Quando NON Usare Qwen 3.5 0.8B
Questo modello NON è adatto per:
- Ragionamento complesso (matematica, logica avanzata)
- Code generation avanzata (meglio Qwen Coder 7B o Claude Sonnet)
- Summarization di documenti lunghi (il contesto è limitato a 32k token)
- Output creativi o narrativi elaborati
Usalo per:
- Chatbot semplici (FAQ, supporto base)
- Assistenti Telegram per comandi rapidi
- Prototipazione di agenti AI (testa workflow prima di passare a modelli grandi)
- Deploy su hardware limitato (VPS economici, Raspberry Pi)
Se hai bisogno di ragionamento più avanzato, considera Qwen 2.5 7B (sempre su Ollama) o passa a modelli cloud come Claude 3.5 Sonnet via OpenRouter.
Alternative e Modelli Simili
Altri modelli piccoli da provare con Ollama + OpenClaw:
- Phi-4 3.8B (Microsoft) - ottimo per code generation su CPU
- Gemma 2 2B (Google) - bilanciato tra dimensione e qualità
- Llama 3.2 3B (Meta) - buon compromesso per uso generale
Per confrontare modelli locali:
ollama list
ollama run <model-name>Cambia il model nel config di OpenClaw e riavvia il gateway. Tutto il resto rimane identico.
Risorse e Approfondimenti
- Repository GitHub di OpenClaw
- Ollama model library
- Documentazione Qwen
- Guida completa OpenClaw + Ollama
Conclusioni
Ho installato Qwen 3.5 0.8B su CPU con OpenClaw e Ollama. Il setup è veloce (15 minuti totali), il modello risponde in pochi secondi, e l'integrazione con Telegram funziona senza configurazioni esotiche.
Quando usarlo: prototipi rapidi, bot semplici, test di agenti AI, deployment su hardware limitato.
Quando evitarlo: ragionamento complesso, code generation avanzata, output creativi elaborati.
Se vuoi un modello locale, piccolo e funzionante senza GPU, Qwen 3.5 0.8B è un ottimo punto di partenza. Parti da qui, testa il tuo workflow, e poi scala a modelli più grandi se serve.
