
Scrapling è una libreria Python per il web scraping che risolve due problemi concreti: i siti che cambiano layout ogni settimana e i sistemi anti-bot che bloccano le tue richieste. Con il supporto MCP integrato e un modello Ollama locale, puoi dare alla tua AI accesso live a internet senza spendere un centesimo in API.
Scrapling traccia gli elementi in un modo che sopravvive ai cambiamenti di struttura della pagina. Include anche un fetcher "stealth" che bypassa Cloudflare e protezioni simili usando un browser reale. Il risultato è un percorso pratico verso un agente di ricerca privato che può leggere il web su comando.
Cosa sono Scrapling, MCP e Ollama
Scrapling è una libreria Python che fa scraping robusto. Invece di selettori CSS fragili che si rompono a ogni aggiornamento del sito, traccia gli elementi in modo semantico. Gestisce anche anti-bot come Cloudflare con tecniche di browser fingerprinting.
MCP sta per Model Context Protocol. È uno standard che permette ai modelli AI di chiamare tool esterni. Invece di generare solo testo, la tua AI può attivare azioni come fare scraping di un sito, leggere un file o interrogare un database. Scrapling include un server MCP integrato.
Ollama è il runtime per eseguire modelli LLM in locale sulla tua macchina. Dalla 3B alla 70B, puoi far girare modelli open source senza mandare dati a terze parti.
Combinando questi tre pezzi, ottieni un setup completamente locale e gratuito in cui il tuo modello può chiedere contenuti freschi dal web in tempo reale.
Setup su Ubuntu (o qualsiasi Linux)
Ho usato un server Ubuntu con GPU perché volevo eseguire un modello Ollama locale sulla stessa macchina. Puoi anche usare modelli CPU-only se necessario, ma una GPU aiuta con velocità e modelli più grandi.
Crea un ambiente virtuale
Isola le dipendenze con Conda, uv o venv. Io preferisco Conda per i progetti Python:
conda create -n scrapling python=3.11 -y
conda activate scraplingOppure con uv (più veloce):
uv venv .venv
source .venv/bin/activateO con venv standard:
python -m venv .venv
source .venv/bin/activateInstalla Scrapling e le dipendenze
Installa la libreria con pip:
pip install scraplingInizializza Scrapling per configurare le dipendenze di automazione browser come Playwright. Questo scarica un browser reale così Scrapling può gestire pagine dinamiche e sistemi anti-bot in modo affidabile:
scrapling installPuoi ignorare eventuali warning benigni durante questo passaggio. Playwright ti dà controllo programmatico su Chrome, Firefox o WebKit per interagire con siti web dinamici.
Hai bisogno di un'infrastruttura AI su misura?
Ti aiuto a progettare e implementare sistemi AI locali o cloud per la tua azienda, con focus su privacy e costi sotto controllo.
Avvia il server MCP
Ora fai partire il server MCP così il tuo modello può chiamare Scrapling come tool. Questo esegue un server sulla porta 8000 accessibile dalla rete, così qualsiasi client compatibile con MCP può innescare uno scrape:
scrapling mcp serve --host 0.0.0.0 --port 8000Una volta in esecuzione, il tuo LLM può emettere richieste tipo "vai a recuperare questo URL ed estrai i paragrafi" e Scrapling restituirà i risultati. Puoi anche chiamarlo dai tuoi script se il tuo client capisce MCP.
Il server MCP espone le capacità di scraping come chiamate di funzione. Il tuo modello locale (via Open WebUI, Continue.dev o altri client MCP) può ora dire "scrapa questa pagina" e ricevere il contenuto estratto.
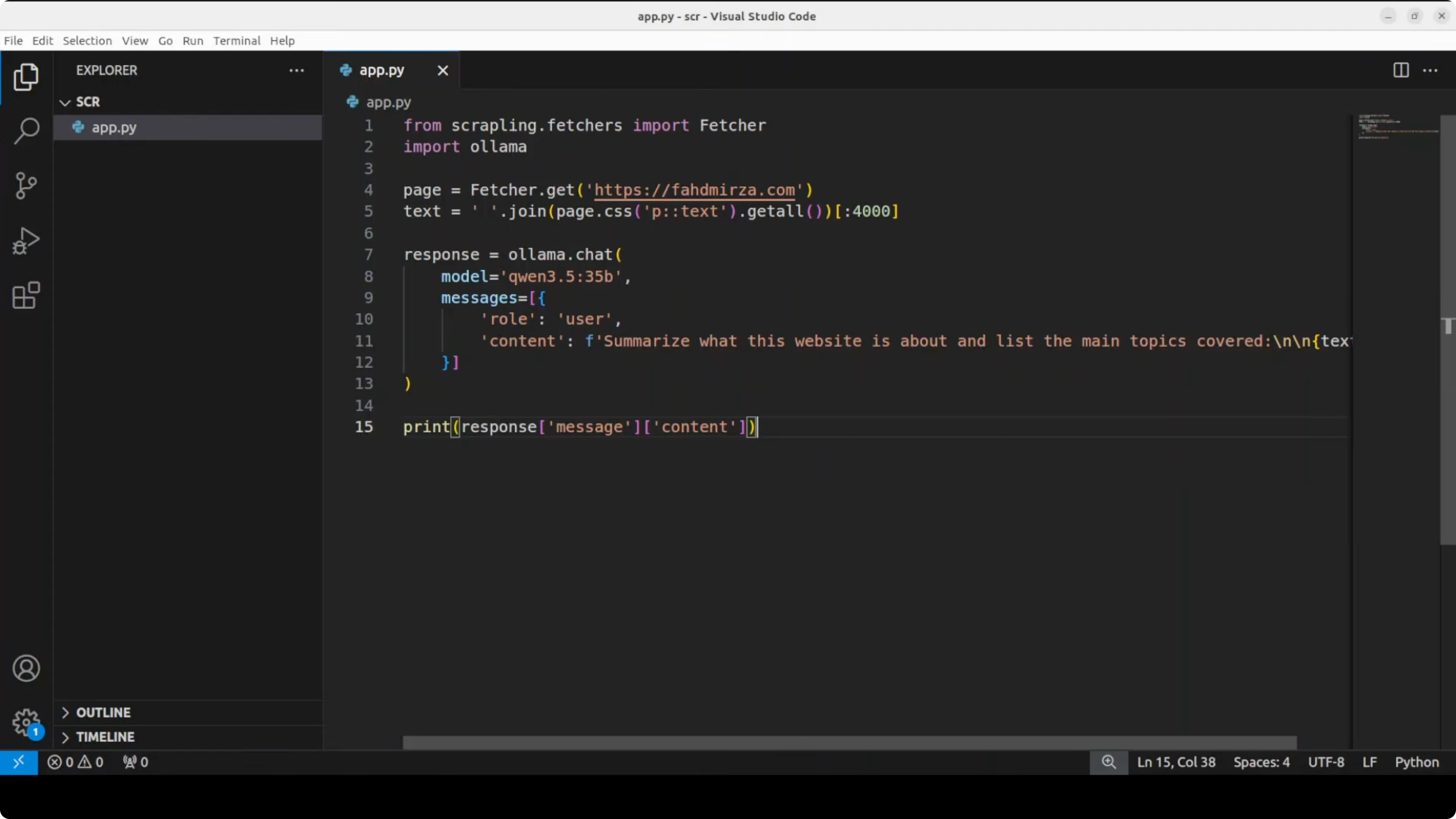
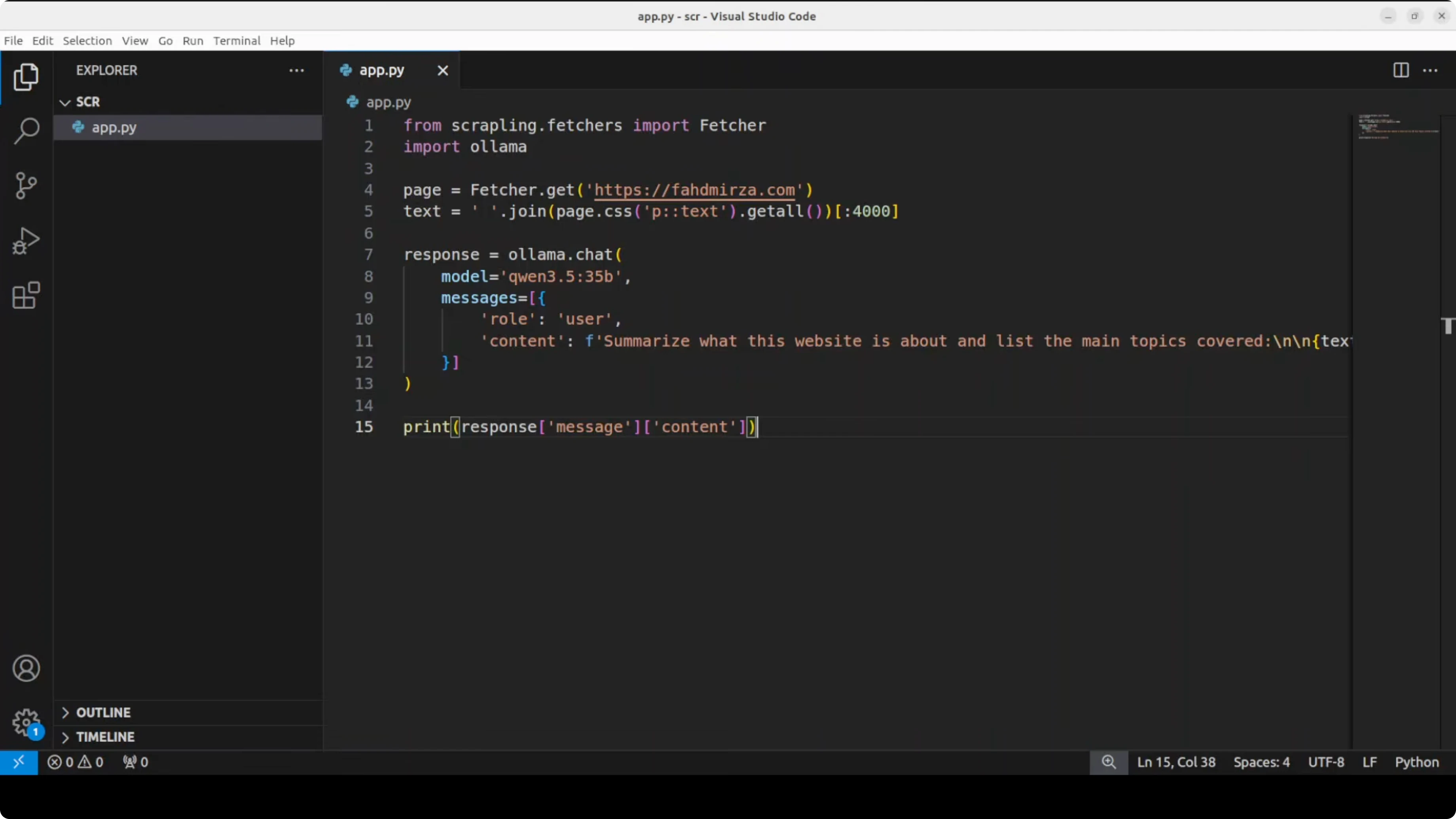
Esempio Python con riassunto via Ollama
Ecco il pattern che ho usato: faccio scraping del testo dei paragrafi da un sito target, poi invio quel testo a un modello locale in Ollama per riassumere di cosa parla il sito. Ho usato un modello locale da 3-4 miliardi di parametri per velocità su una singola GPU, ma puoi passare a un modello più grande se ti serve maggiore profondità.
Prima assicurati che Ollama sia installato e che un modello sia scaricato. Per esempio:
# installa Ollama seguendo le istruzioni ufficiali, poi:
ollama pull llama3.2:3bPoi uno script Python minimale per riassumere il testo scrapato con Ollama. Sostituisci get_page_text(...) con la tua chiamata Scrapling o la tua chiamata client MCP che restituisce il testo dei paragrafi estratti da un URL:
import requests
import textwrap
# Sostituisci con la tua chiamata di estrazione Scrapling, es. via client MCP.
# Dovrebbe restituire una stringa contenente il testo dei paragrafi dalla pagina target.
def get_page_text(url: str) -> str:
# Esempio placeholder. Implementa con il tuo workflow Scrapling.
# Ad esempio, tramite una chiamata client MCP o l'API Python di Scrapling.
raise NotImplementedError("Integra Scrapling qui per restituire il testo della pagina")
def summarize_with_ollama(text: str, model: str = "llama3.2:3b") -> str:
payload = {
"model": model,
"prompt": textwrap.dedent(f"""
Riassumi i principali argomenti del seguente contenuto web.
Mantienilo conciso e fattuale.
Contenuto:
{text}
""").strip(),
"stream": False
}
resp = requests.post("http://localhost:11434/api/generate", json=payload, timeout=600)
resp.raise_for_status()
data = resp.json()
return data.get("response", "").strip()
if __name__ == "__main__":
url = "https://example.com"
page_text = get_page_text(url)
summary = summarize_with_ollama(page_text)
print(summary)Quando ho eseguito questo flow, lo scraper ha restituito uno status HTTP 200, ha navigato attraverso la ricerca quando necessario e ha attraversato i link sulla pagina. Il modello locale ha riassunto gli argomenti del sito, notato gli sponsor e evidenziato che ospita contenuti educativi.
Questo dà al tuo modello contesto privato e live invece di affidarsi a dati di training obsoleti.
Vuoi automatizzare la ricerca con AI locale?
Posso aiutarti a configurare pipeline di scraping e analisi con modelli locali per mantenere i dati privati e i costi sotto controllo.
Fetching stealth, etica e affidabilità
Scrapling include un fetcher "stealth" che può bypassare protezioni come Cloudflare Turnstile usando un browser reale con fingerprint spoofati. Gestisce anche impostazioni di produzione automaticamente senza configurazione extra.
Usa queste capacità in modo responsabile e rimani entro i confini legali ed etici stabiliti dai siti target. Controlla sempre i file robots.txt e i termini di servizio. Lo scraping aggressivo può sovraccaricare i server e violare i ToS.
Siccome Scrapling traccia elementi invece di selettori fragili, gli scraper continuano a funzionare dopo molti cambiamenti di layout. Questo riduce la manutenzione per agenti a lungo termine e dataset builder. È gratuito e open source, il che si adatta bene a progetti locali e privati.
Casi d'uso pratici
Agente di ricerca locale: costruisci un agente che accetta un argomento, fa scraping di più siti pertinenti (che permettono il crawling), aggrega il contenuto e chiede a un LLM locale di riassumere e confrontare. Eviti costi API, mantieni i dati privati e riduci le allucinazioni fondando le risposte su contenuto fresco.
Questo è ideale per basi di conoscenza personali, brief tecnici e panoramiche di mercato veloci.
Monitoraggio di prezzi o notizie: scrapia periodicamente siti di e-commerce o feed di notizie, estrai dati strutturati e fai analizzare a un modello locale trend o cambiamenti significativi.
Dataset custom per training: raccogli dati specifici del dominio da fonti pubbliche, puliscili con un modello locale e crea dataset per fine-tuning. Tutto privato, senza mandare dati sensibili a terze parti.
Puoi anche eseguire workflow da riga di comando e bypassare MCP se preferisci pipeline CLI pure. Tool come OpenClaw si integrano bene quando vuoi run riproducibili e un pannello di controllo semplice per il tuo stack di agenti.
Scopri i miei progetti AI
Dai un occhio ai progetti su cui sto lavorando e alle tecnologie che utilizzo per automazione e AI locale.
Scelta del modello Ollama
Modelli piccoli (2B-4B): veloci e leggeri. Pro: risposte rapide su hardware modesto, bassa VRAM, buoni per riassunti brevi ed estrazione. Contro: ragionamento più debole, possono perdere sfumature in articoli lunghi.
Esempi: Llama 3.2 3B, Phi-3 Mini, Gemma 2B.
Modelli medi (7B-13B): bilanciano velocità e qualità. Pro: riassunti più forti, migliore copertura degli argomenti, ancora praticabili su una singola GPU o CPU forte. Contro: uso di memoria maggiore e throughput più lento rispetto ai modelli piccoli.
Esempi: Mistral 7B, Llama 3.1 8B, Qwen 2.5 7B.
Modelli grandi (30B+): possono produrre sintesi più ricche. Pro: maggiore profondità e coerenza per report long-form. Contro: necessità di VRAM pesante, più lenti su hardware consumer e possono essere eccessivi per riassunti veloci.
Esempi: Llama 3.1 70B, Qwen 2.5 32B.
Scegli una dimensione in base alla tua macchina e alla lunghezza del task. Per riassunti semplici di pagine e estrazione di metadata, un modello da 3B a 8B funziona bene. Per sintesi multi-sito e report più lunghi, salta a 13B o superiore se la tua GPU può gestirlo.
Considerazioni finali
Scrapling dà al tuo modello locale accesso robusto al web con tracking degli elementi e fetching stealth. MCP trasforma quella capacità in un tool chiamabile così il tuo LLM può chiedere contesto fresco su richiesta.
Abbinato a Ollama, ottieni workflow di ricerca privati, senza API, che rimangono resilienti mentre le pagine cambiano. È un setup potente per chiunque voglia mantenere i dati in casa e costruire agenti che vedono davvero il web attuale.
Risorse utili:
- Repository GitHub Scrapling: https://github.com/D4Vinci/Scrapling
- Documentazione Ollama: https://ollama.com/
- Spec MCP: https://modelcontextprotocol.io/
- OpenClaw per orchestrazione agenti: https://openclaw.ai/
Se vuoi sperimentare, inizia con un modello piccolo (Llama 3.2 3B o Phi-3 Mini), configura il server MCP di Scrapling e prova a riassumere qualche pagina web. Poi scala in base alle tue necessità.
