
Punti Continue.dev a http://localhost:11434/v1/, ottieni suggerimenti di codice serviti da Ollama, spedisci una feature, vai avanti. Poi leggi del QVAC SDK e vuoi provarlo - senza riscrivere il setup dell'editor, senza toccare il codice client, senza cercare un nuovo plugin per l'IDE. Buone notizie: non devi. Il server OpenAI compatibile di QVAC ha anche lui come default la porta 11434, parla lo stesso shape v1/chat/completions, ed è stato pensato apposta perché un'install di Continue.dev, LangChain o Open Interpreter già configurata per Ollama possa parlare con QVAC con un solo cambio di config.
Nei prossimi 15 minuti installi lo SDK, avvii il server, dimostri il surface OpenAI con curl, e lo cabli in Continue.dev. La sandbox completa - install reale, download del modello reale, risposte reali - gira end-to-end su un Mac ed è riproducibile da questo articolo. Se non hai mai sentito parlare di QVAC prima, il cornerstone Cos'è il QVAC SDK? copre il pitch più ampio.
Perché sostituire Ollama con QVAC
Ollama è buono. Fa girare modelli in locale, espone un'API HTTP OpenAI-compatibile, ha una CLI accogliente. La cosa che non fa: generare immagini, trascrivere audio, tradurre senza cloud, fare RAG out of the box, o fine-tuning di adapter LoRA su un telefono. Il QVAC SDK fa tutte queste cose, dietro lo stesso import. Quindi cambiare apiBase in Continue.dev è più di uno scambio di brand - è il momento in cui il tuo stack AI locale smette di essere solo-LLM e inizia a essere tutto-on-device. Il drop-in è voluto: il server OpenAI di QVAC vive sulla porta 11434 di default, come Ollama, e il formato wire è identico a OpenAI.
L'unico catch: solo uno dei due può tenere la porta 11434 alla volta. La storia di migrazione è "ferma Ollama, avvia QVAC". Continue.dev non se ne accorge.
Prerequisiti
- macOS 14+ su Apple Silicon (backend GPU Metal), o Linux con Vulkan, o Windows 10+ con Vulkan. Questo tutorial è stato fatto su macOS arm64 con Metal.
- Node.js ≥22.17 - il floor del runtime QVAC. Una Node più vecchia installa ma
loadModel()esplode a runtime. - VSCode o Cursor con la extension Continue.dev. Cursor usa il marketplace di VSCode, quindi la extension si installa allo stesso modo.
- Circa 400 MB di disco libero per il modello demo più piccolo (Qwen3 0.6B Q4_0).
- Una porta 11434 libera se vuoi il drop-in vero. Se Ollama gira, fermalo prima (
brew services stop ollamaopkill -9 ollama) o fai partire QVAC su una porta diversa.
Installa SDK e CLI
Crea un progetto pulito, installa entrambi i pacchetti, verifica che il binario qvac sia raggiungibile:
mkdir qvac-openai-demo && cd qvac-openai-demo
npm init -y && npm pkg set type=module
npm install @qvac/sdk @qvac/cliL'install tira giù 212 pacchetti in ~45 secondi e segnala zero vulnerabilità. Lo SDK al momento è 0.9.1 e la CLI 0.2.4.

Il pacchetto @qvac/cli cabla il binario qvac in node_modules/.bin/ del progetto, quindi npx qvac funziona senza install globale. Due subcommand rilevanti:
npx qvac serve openai --help # il server HTTP OpenAI-compatibile
npx qvac bundle sdk # tree-shaking dei plugin per i deploy mobileQuello che ci interessa oggi è serve openai.

Nota la porta di default: 11434. Identica a Ollama. Ed è il pitch del drop-in, riassunto in un default della CLI.
Configura un modello
Il server CLI carica i modelli per alias da un file qvac.config.{json,js,mjs,ts} nella root del progetto. Il file è condiviso tra runtime SDK e bundler CLI - il blocco serve.models è quello che qvac serve openai legge.
Per questo tutorial usiamo QWEN3_600M_INST_Q4, un Qwen3 0.6B Instruct quantizzato a Q4_0. Pesa 382 MB e gira veloce su qualunque Mac recente, il che lo rende la scelta giusta per una demo. Il registry completo dei modelli ha ~653 entry, incluse varianti Qwen3 4B/8B, Llama 3.2 1B, Qwen3-VL multimodale, e tune per tool-calling - ognuna entra in questa config allo stesso modo.
Salva come qvac.config.ts:
export default {
serve: {
models: {
'qwen3-0.6b': {
model: 'QWEN3_600M_INST_Q4',
default: true,
preload: true,
config: { ctx_size: 8192 },
},
},
},
}L'alias qwen3-0.6b è quello che Continue.dev andrà a referenziare. Il valore di model deve essere un nome valido di costante SDK dal registry di @qvac/sdk - se sbagli a digitarlo, la CLI ritorna un errore "unknown model constant" con un suggerimento.
Alza la context size per Continue.dev. Il
ctx_sizedi default nel plugin llamacpp-completion di QVAC è 1024 token. Continue.dev manda ~1500 token di system prompt a ogni request (definizioni dei tool, context del progetto, regole di formattazione). Senza l'override qui sopra vedicontext overflow at prefill step: prompt tokens 1524, max context tokens 1024nei log del server e un toast "internal error" in Continue. Alzare a 8192 copre Continue più una chat history normale. Per chiamatecurldirette con prompt corti il default va bene; per qualunque assistant nell'IDE, impostalo.
Avvia il server OpenAI-compatibile
Un comando. Il primo run scarica il modello (~382 MB, un minuto su una connessione decente); i run successivi vanno a cache.
npx qvac serve openai --model qwen3-0.6b --verbose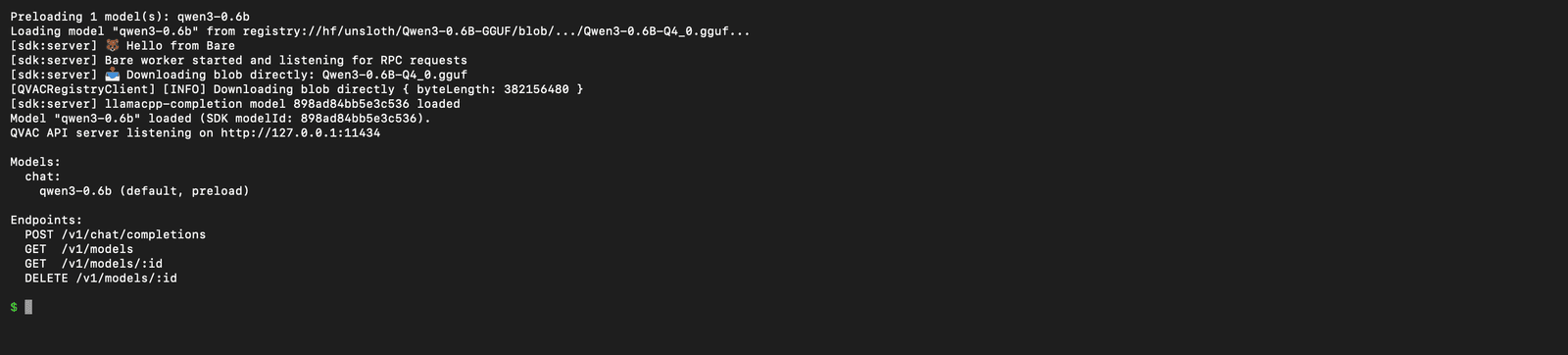
Il server fa partire un Bare worker (il runtime JS leggero di Holepunch), scarica il blob GGUF dal registry QVAC, lo carica attraverso il fork llama.cpp di Tether, e registra quattro endpoint sotto /v1/:
POST /v1/chat/completions- quello che usano Continue.dev (e ogni client Ollama-compatible)GET /v1/modelseGET /v1/models/:id- discovery dei modelliDELETE /v1/models/:id- scarica un modello dalla RAM
Se hai un conflitto con Ollama sulla 11434, aggiungi --port 11435 al comando - tutto il resto (config, alias, pickup della GPU) è uguale.
Nota: la prima request
chat/completionsdopo il boot scalda la prompt cache; la latency delle request successive scende di un ordine di grandezza. È comportamento normale dillama.cpp, non una stranezza di QVAC.
Verifica il surface OpenAI con curl
Prima di puntare l'editor al server, parlagli con curl per confermare il formato.
curl -s http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-0.6b",
"messages": [
{"role": "user", "content": "In one sentence: what is QVAC?"}
],
"max_tokens": 80
}' | jq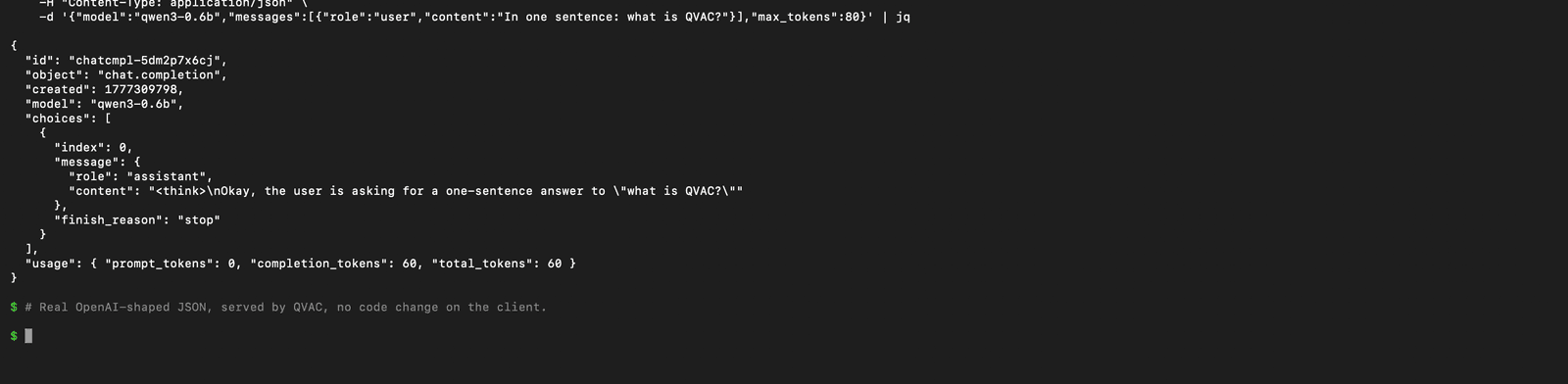
Lo shape è quello OpenAI - id, object: "chat.completion", choices[0].message, blocco usage. Drop-in.
Un heads-up dal mondo reale: Qwen3 ha la thinking mode attiva di default, quindi il content dell'assistant inizia con un blocco <think>...</think> prima della risposta vera. Continue.dev (e quasi tutti i client Ollama-compatible) lo renderizzano verbatim nella chat panel, a meno che tu non lo disabiliti. Per sopprimerlo, aggiungi /no_think al messaggio user, o usa una variante di modello senza thinking. Altre famiglie (Llama 3.2, Gemma) non hanno thinking mode e rispondono direttamente.
Lo streaming funziona allo stesso modo - passa "stream": true e ricevi chunk SSE in formato OpenAI (data: {…}\n\n) fino a [DONE].
Hai bisogno di aiuto con l'integrazione AI?
Contattami per una consulenza su come spedire AI locale e privata nel tuo prodotto.
Cabla in Continue.dev
Continue.dev legge la config dell'assistant da ~/.continue/config.yaml (il formato YAML ha sostituito il vecchio JSON nel 2025). Aggiungi una singola entry di modello che punta a QVAC.
name: qvac-local
version: 1.0.0
schema: v1
models:
- name: QVAC Qwen3 0.6B
provider: openai
apiBase: http://localhost:11434/v1/
apiKey: not-needed
model: qwen3-0.6b
roles:
- chat
- edit
- autocomplete
Tre cose da chiamare fuori da questo YAML:
provider: openaiè l'adapter OpenAI-compatible, non l'API cloud di OpenAI. Il vocabolario di Continue.dev qui è infelice - è lo stesso provider che usavi per Ollama se lo trattavi come endpoint OpenAI-compatible.apiBaseè l'unica riga che cambia davvero quando swappi engine. Puntato alocalhost:11434/v1/parla con qualunque server locale tenga la porta.apiKeyè richiesta dallo schema validator ma non viene usata su un server locale. Una qualunque stringa non vuota funziona.
Salva il file, ricarica l'editor (Cmd+Shift+P, "Reload Window"), e "QVAC Qwen3 0.6B" appare nel model picker di Continue. Apri la side panel, fai una domanda di codice, guarda i token streammare.
Cosa cambia davvero rispetto a Ollama
L'idraulica è identica. Le capability no.
| Ollama | QVAC | |
|---|---|---|
| Porta di default | 11434 | 11434 |
OpenAI /v1/chat/completions | sì | sì |
OpenAI /v1/embeddings | sì (modello a parte) | sì (plugin a parte) |
| Streaming SSE | sì | sì |
| Generazione immagini (Stable Diffusion / FLUX) | no | sì (@qvac/sdk/sdcpp-generation/plugin) |
| Speech-to-text (Whisper) | no | sì (@qvac/sdk/whispercpp-transcription/plugin) |
| Traduzione on-device (Bergamot) | no | sì (@qvac/sdk/nmtcpp-translation/plugin) |
| Mobile (iOS, Android) | solo desktop / server | sì via Expo |
| Fine-tuning LoRA on-device | no | sì |
| Inferenza P2P delegata | no | sì (Hyperswarm) |
| API HTTP OpenAI-compatibile | sì (ollama serve) | sì (qvac serve openai) |
| Model registry | sì (Ollama Hub) | sì (Hyperdrive su Hyperswarm, ~653 modelli in v0.9.0) |
| Licenza | MIT | Apache-2.0 |
Gli endpoint del server OpenAI in QVAC v0.9.1 sono limitati a chat completions e gestione modelli. Embedding, trascrizione, traduzione, e generazione immagini sono esposti tramite l'API JS dello SDK (embed(), transcribe(), translate(), diffusion()), non ancora via HTTP server. Se il tuo client parla OpenAI per la chat e chiamate dirette allo SDK per il resto, QVAC è già il server locale più generale che puoi far girare oggi.
Dove andare adesso
- Il cornerstone Cos'è il QVAC SDK? cammina attraverso ogni capability con esempi di codice.
- Per un tutorial che usa l'API
transcribeinvece, vedi Costruire uno strumento di trascrizione offline con QVAC + Whisper. - Se il tuo stack locale precedente faceva girare Qwen 3.5 0.8B su OpenClaw + Ollama in CPU, lo stesso swap di
apiBaselo sposta su QVAC - OpenClaw usa l'interfaccia OpenAI-compatible end-to-end. - Il riferimento canonico sono i docs di QVAC, con l'export plaintext consolidato a llms-full.txt per gli assistant degli IDE.
- Il source su GitHub: tetherto/qvac.
- Lo schema completo della config dei modelli di Continue.dev sta su docs.continue.dev - tutto in questo articolo usa l'adapter
provider: openaidocumentato.
Il risultato pulito di questo esercizio: non hai scritto nessuna riga di codice oltre a un file YAML. Il tuo editor parla con QVAC per la chat, e lo stesso SDK è a un import di distanza il giorno in cui ti serve generazione immagini, trascrizione, o fine-tuning nello stesso progetto.
Scopri i miei progetti
Dai un'occhiata ai progetti su cui sto lavorando e alle tecnologie che uso.